
Clearing the Skies for Cloud Data Warehousing with Dr. Barry Devlin

Executive Summary
Dr. Barry Devlin compares and contrasts various data architecture approaches, including Data Fabric, Data Lake House, and Data Mesh. It explores the evolution of data architecture in IBM, data flow and architecture in information preparation, and the pros and cons of the Data Fabric approach. Additionally, it discusses the challenges of metadata, the concept of Data Mesh, and analysis of Data Mesh Architecture. The webinar concerns using AI and ML in solving metadata problems, complexity and chaos in data management, and the complexity of finding solutions in cloud data warehousing.
Webinar Details
Title: Clearing the Skies for Cloud Data Warehousing with Dr. Barry Devlin
Date: 19 September 2023
Presenter: Dr. Barry Devlin
Meetup Group: Big Data & Data Science
Write-up Author: Howard Diesel
Contents
Reflection on Meeting with Barry and Introduction of Data Warehousing Approaches.
Comparison of Data Fabric, Data Lake House, and Data Mesh Architectural Approaches.
Evolution of Data Architecture in IBM.
Data Flow and Architecture in Information Preparation.
Comparison of Data Warehouse, Data Lake, and Logical Data Warehouse Patterns.
Overview of Data Lake House, Fabric, and Mesh Patterns.
The Evolution and Characteristics of Data Lakes.
Data Lake House Architecture and Implementation.
Comparison of Data Lakehouse and Data Fabric Concepts.
Data Fabric and the Evolution of the Logical Data Warehouse.
The Pros and Cons of the Data Fabric Approach.
The Challenges of Metadata and the Concept of Data Mesh.
Understanding the Concept of Data Mesh.
Understanding the Data Mesh Concept
Analysis of Data Mesh Architecture.
Data Fabric, Data Lake House, and Data Mesh According to Gartner's Hype Cycle.
Notes on Architecture and Ontology in Data Warehousing.
Thoughts on John O'Gorman's Ontology and the Word "Choreography".
Concerns about the use of AI and ML in solving metadata problems.
The Use of AI in Self-Driving Cars and Informatica's Approach.
Complexity and Chaos in Data Management
Cloud Data Warehousing and the Complexity of Finding Solutions.
Reflection on Meeting with Barry and Introduction of Data Warehousing Approaches
Howard is pleased to see Barry again, acknowledging his contribution to data warehousing. Dr. Barry Devlin is one of the pioneers of this approach, predating Mr. Inman, and shares a history with the speaker at IBM. Howard mentions missing Barry in Cape Town and hopes to have him back one day. Barry acknowledges his time in South Africa and wants to visit again. Technical difficulties are mentioned before sharing screens for the presentation. Barry discusses three cloud data warehousing approaches: Data Fabric, Mesh, and Lake House. He reflects on how these approaches resemble past data warehousing debates and teases the complexity of the current landscape with multiple vendors and consultants.

Figure 1 About the Speaker
Comparison of Data Fabric, Data Lake House, and Data Mesh Architectural Approaches
Barry wants to discuss and differentiate between three architectural design patterns: Data Fabric, Data Lake House, and Data Mesh. He plans to highlight the pros and cons of each approach and share their opinions on which approach is better in specific circumstances. Barry acknowledges the commonly asked question of the meaning of these approaches and emphasises the importance of considering architecture as a basis for comparison. He intends to present an unbiased understanding of their thought process and will make the slide deck with all relevant links available after the presentation. Barry also briefly mentions their architecture published in 2013 and its suitability for cloud environments.

Figure 2 Defining Data Fabric, Data Lakehouse and Data Mesh

Figure 3 "A soupçon of architecture as a basis for comparison"
Evolution of Data Architecture in IBM
An architecture for a business information system was developed by IBM, which consisted of two layers - an Enterprise Data Warehouse with reconciled data and Data Marts based on user needs. The architecture featured vertical and horizontal segmentation and unidirectional data flow. Metadata was represented as a separate box on the side. This architecture was successful until the emergence of big data in the 2010s, which led to the proposal of the concept of "information pillars" in 2013. The information pillars allowed mixing and matching technologies and emphasised metadata integration throughout the system.
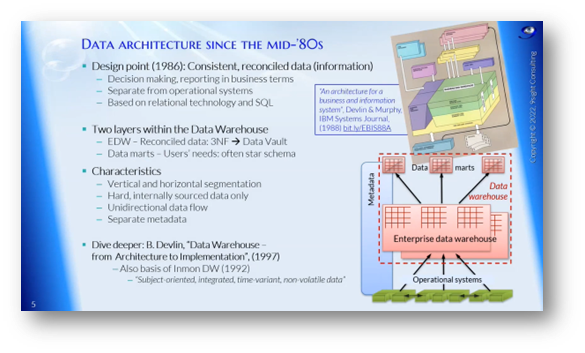
Figure 4 Data Architecture since the Mid-'80s

Figure 5 Introducing Information Pillars
Data Flow and Architecture in Information Preparation
The traditional approach to data warehousing involved reconciling data upfront, leading to delays in modelling and design. However, a new approach aims to move away from layered architecture and focus on necessary storage and transformation. This involves considering external data and different data types, such as human-sourced information and process-mediated data. The new architecture consists of instantiation, assimilation, and reification, representing the tools, reconciled information creation, and cross-pillar access. To manage the different processes in information preparation, choreography is used. This new architecture aligns with older data warehouse patterns.

Figure 6 Information Preparation Creates, Maintains and Mediates Access to All Information
Comparison of Data Warehouse, Data Lake, and Logical Data Warehouse Patterns
Modern data architecture has three main approaches: the data warehouse, the data lake, and the logical data warehouse. The data warehouse manages ongoing business operations with clean and reconciled data. In contrast, the data lake encompasses human-sourced and machine-generated data and is typically utilised for predicting and influencing the future. The logical data warehouse combines the data lake, data warehouse, and other data sources. However, accessing this information poses challenges due to the increasing overlap between operational and informational data. Governance and management are crucial for success in all three approaches.
Overview of Data Lake House, Fabric, and Mesh Patterns
As operational and informational processing merge, analytics face complex data and model flows. Three solutions have been proposed: Lake House, Fabric, and Mesh. Each solution will be discussed and mapped onto an architectural picture. Barry presents their pros and cons. The simplest pattern, Data Lake House, is depicted as a solution for less structured data, but the lack of transaction support, data quality, and updates can be challenging. This has resulted in users resorting to multiple systems, causing complexity within the data lake. Components include BI, data marts, real-time databases, and ETL.
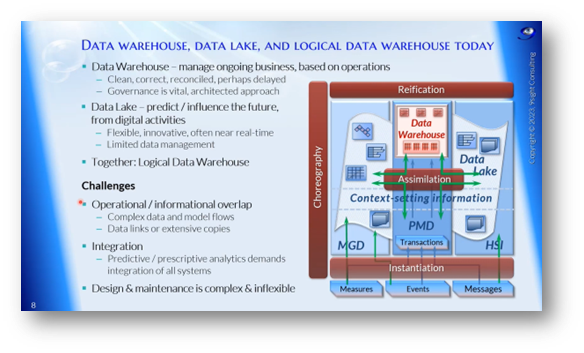
Figure 7 Data Warehouse, Data Lake, and Logical Data Warehouse Today

Figure 8 Data Lakehouse, Fabric, Data Mesh - Meaningful Definitions & Architected Pictures
The Evolution and Characteristics of Data Lakes
Barry goes on to explore the evolution of data lakes over the last decade and how they have become complicated in architectural design. The significance of data breaks and their products in creating an architecture is discussed. Barry suggests key characteristics of data lakes, including their ability to handle asset transactions for streaming mechanisms. Unlike data warehouses, data lakes require asset transactions to protect the data warehouse during the update process. Additionally, data lakes support BI-type interactions, meaning highly structured and well-managed data. Overall, this piece provides valuable insights into the features and challenges associated with data lakes.

Figure 9 Data Lakehouse - As Described by Proponents
Data Lake House Architecture and Implementation
A Data Lake House is a data storage architecture that supports structured and non-structured workloads for business intelligence tools and direct data access. It includes end-to-end streaming capabilities and can involve batch-oriented processes with different data types. The architecture involves loading all necessary data into the data lake, which serves as an object store for human-sourced, machine-generated, and process-mediated data. These data are then assimilated into data warehouse structures, which may use object storage or a relational database. Databricks suggests building relational-like capabilities in Spark for a Data Lake House.
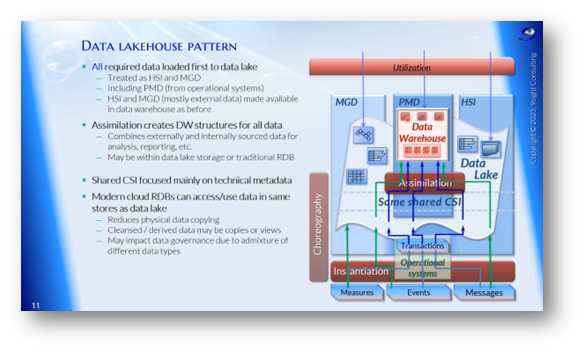
Figure 10 Data Lakehouse Pattern
Comparison of Data Lakehouse and Data Fabric Concepts
The Data Lakehouse is a modern Cloud-based concept that prioritises technical metadata and supports relational databases. However, data governance approaches vary, with some not prioritising data quality and governance as much as data warehouses. The benefits of implementing a Data Lakehouse include scalability, storage and processing separation, support for analytics, and open-source table formats. Additionally, it can address data swamp issues with its structured data warehouse-like design. However, challenges include handling ingestion problems, reconciling data from different systems, and requiring specific implementation skills. The Data Fabric concept aims to provide consistency in data management by using a data catalogue as the foundation for accessing and representing data in a connected Knowledge Graph, emphasising semantic and ontological consistency.

Figure 11 Data Lakehouse - Pros and Cons

Figure 12 Data Fabric - As Described by Proponents
Data Fabric and the Evolution of the Logical Data Warehouse
Data management has evolved with dynamic data integration and the Data Fabric architecture. An active catalogue that changes with the world can be achieved by utilising analytics, knowledge graphs, AI, and ML algorithms. Automated orchestration of data eliminates the need for manual building and tooling of integration tools. Data Fabric retains and accesses all sources and copies of data, regardless of their type, using data virtualisation and reification. Strong metadata or context-setting information is essential for effective data governance, and centralised metadata enables widespread self-service usage and enhances verification capabilities.
The Pros and Cons of the Data Fabric Approach
The Data Fabric approach requires new technologies like choreographed workflows and semantic knowledge graphs, but active metadata management is still a challenge for many organisations. Machine learning and AI are important components of this approach. Its advantages include evolution from existing systems, integration of past patterns, extensive vendor support, and availability of necessary skills. However, some technologies and software are still immature and may not appear novel to organisations. This approach could be difficult to sell to organisations with ongoing warehouse or lake challenges. Despite attempts at standards and metadata catalogues since the late 80s, products and vendors still lag in required function and interoperability.
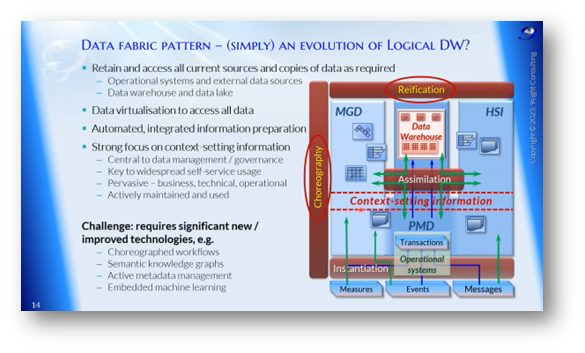
Figure 13 Data Fabric pattern

Figure 14 Data Fabric - Pros and Cons
The Challenges of Metadata and the Concept of Data Mesh
Metadata management has been a persistent challenge in data warehousing for decades. Establishing a good foundation for metadata and information management within organisations is difficult. Data Mesh is a new concept that emphasises decentralisation, cloud adoption, microservices, DevOps, and domain-driven design principles to avoid centralised failure modes. The goal is to shift from central to local controls and learn from modern software engineering practices.
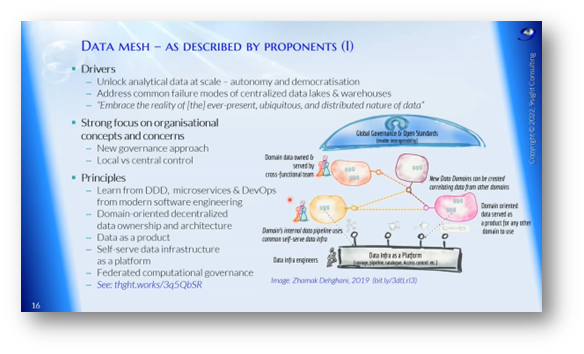
Figure 15 Data Mesh - As Described by Proponents One
Understanding the Concept of Data Mesh
A domain is a grouping of business functions with its own language. Cross-functional teams are responsible for each domain, which involves different business functions. Each domain has internal data pipelines consisting of extract, load, and transform processes. Data products managed by domain owners follow specific product management approaches. The creation of other domains involves correlating data from multiple domains. Data Mesh is a decentralised approach that does not have a centralised ETL environment, and domain owners describe data transfer. Federated governance with computational policies embedded in data products and architectural planes is incorporated in Data Mesh. A data product combines code, data, metadata, and infrastructure, delivering a specific data product with management included. Data Mesh is a complex concept that requires a shift away from traditional data warehousing thinking.
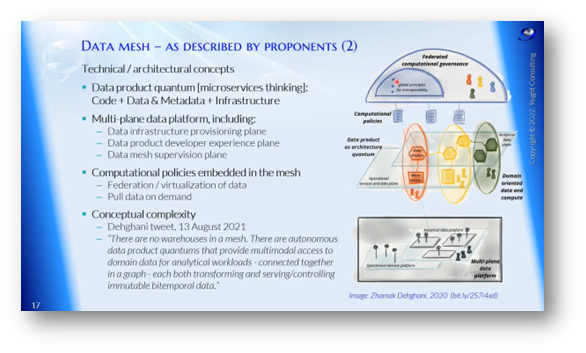
Figure 16 Data Mesh - As Described by Proponents Two
Understanding the Data Mesh Concept
Data Mesh is a new data architecture concept defined by Zhamak Dehghani. It involves autonomous data product quantums that offer multimodal access through SQL, API, or file. Unlike traditional data warehouses, Data Mesh does not have centralised data ownership. Instead, data is owned within domains for analytical workloads, connected in a graph. Data Mesh also introduces the concept of immutable BI-temporal data uniquely. However, confusion may arise with Data Fabric, which deals with transforming and serving immutable BI-temporal data. To learn more about Data Mesh, Zhamak Dehghani’s book is free from a vendor.
Analysis of Data Mesh Architecture
The Data Mesh architecture takes a decentralised and distributed approach to data management. It creates a Mesh of data sets that can be accessed through reification. This requires data virtualisation, as data is spread across multiple sources and requires choreography to build the Mesh. Successful implementation requires extensive changes to design thinking and new technologies. Pros of the Data Mesh include natural decomposition of responsibility, business-centric design, and automation of data governance. However, cons include the need for in-house development, lack of metadata standards and tools, difficulty reconciling data across sources, potential developmental inefficiency and skills dilution, and potential chaos in organisations with immature data governance.
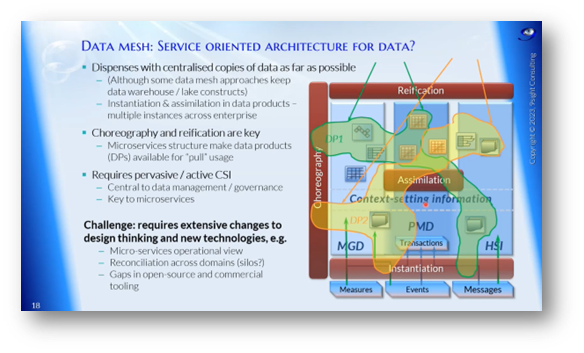
Figure 17 "Data Mesh: Service Oriented Architecture for Data?"

Figure 18 Data Mesh - Pros and Cons
Data Fabric, Data Lake House, and Data Mesh According to Gartner's Hype Cycle
Data Fabric, a tool that reflects the newness of AI and ML technologies, is progressing towards the plateau of productivity and is the preferred tool, according to Gartner's Hype Cycle of 2022. Data Lake House is at an earlier stage but is predicted to mature within 2-5 years. It combines the benefits of cloud storage and compute technology with limited governance, allowing it to reach the plateau of productivity faster. On the other hand, Data Mesh is still in the Innovation trigger phase and is likely to become obsolete before reaching the plateau of productivity. Comparing the three approaches, Data Fabric is an evolution of the Logical Data Warehouse, while Data Lake House is simpler and closer to current data lakes and warehouses. Data Mesh requires domain-driven design, a significant organisational shift with strong governance principles.

Figure 19 Gartner's Hype Cycle for Data Management, 2022
Notes on Architecture and Ontology in Data Warehousing
During a recent event on data warehousing, Barry expressed support for decentralisation in this field. The first volume of Cloud Data Warehousing has been released, with a second volume planned to explore technologies in greater depth. A 25% discount is available on the PDF version of the book with a code from Technics Publications. In addition, Barry will be appearing at an upcoming event in Utrecht on November 1st and 2nd. A business intelligence book can also be purchased at a discount with a code.

Figure 20 Conclusions

Figure 21 'Cloud Data Warehousing, Volume 1'

Figure 22 'From BI to Business Unintelligence'

Figure 23 Closing Slide
Thoughts on John O'Gorman's Ontology and the Word "Choreography"
Barry has collaborated with John O'Gorman on ontology work, which he believes will be a powerful tool. John's extension of the Zachmann ontology is impressive, but it is difficult to compare to others in the field. During a conversation about problem-solving, Gill commented on the flexible approach that "choreography" allows, which resonated with Gill due to her background in dancing. In 2012-2013, Barry chose "choreography" over "orchestration" for its implied freedom and creativity, though the choice of language was not deeply considered then. Barry appreciated Gill's comment and the opportunity to reconnect after many years.
Concerns about the use of AI and ML in solving metadata problems
A question arises to whether Data Fabric with active metadata can effectively solve metadata problems. He expresses scepticism about AI's ability to end world hunger and warfare, as it can only identify patterns in existing data. Barry also doubts whether there is enough historical data to support the claims about AI and ML's capabilities in Data Fabric. Although impressed by Informatica's use of AI in metadata, Barry believes that human intuition and synthetic data may still be necessary. He expresses concerns about generative AI and synthetic data, citing articles that suggest using generative AI could lead to model breakage.
The Use of AI in Self-Driving Cars and Informatica's Approach
An attendee notes that AI is being used in self-driving technology, with Tesla initially relying on well-created data to allow the AI to learn and solve problems. However, the size of the training set and metadata availability proved important. Informatica succeeded with its integration as a service environment, utilising the metadata of many companies. It is important to be cautious about AI's capabilities in self-driving and various other domains. Informatica's Claire model is primarily based on machine learning and analyses patterns within the data itself, but the details of its functionality and inputs are unknown.
Complexity and Chaos in Data Management
A discussion starts on the topic of data analysis, specifically the importance of automation and speed to keep up with changing data. While data management aims to reduce chaos, businesses are inherently chaotic. Data Mesh architectures are discussed as a way to adapt to chaos. Managing data from multiple sources requires reconciliation and synchronisation, which takes time. It's important to determine which data needs consistency and invest resources in managing it. Process-mediated data is introduced to prioritise consistency for some data, while other data may not require the same level of governance.
Cloud Data Warehousing and the Complexity of Finding Solutions
Barry closes the webinar with a warning about the addictive nature of cloud data warehousing and stresses the importance of responsible usage. With the increasing number of competing cloud solutions, he believes there is no one-size-fits-all solution to all data warehousing problems. Both data consumers and providers must revisit fundamental principles and problems to find balance.
If you want to receive the recording, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!