
Data Modelling - Just the Facts - A Demonstration

Executive Summary
This webinar outlines a comprehensive framework for effective Data and Information Management, focusing on a practical use case involving student apprenticeships within a new digital application project. Marco Wobben demonstrates information modelling and database structures, data semantics, and constraints in data architecture. The integration of advanced tools such as ChatGPT and data warehouse builders enhances the management and analysis of information.
Additionally, Marco emphasizes the significance of international language modelling and translation in software development, alongside strategies for temporal data tracking and communication. Understanding and meeting data requirements is critical, blending business strategy with technical data management practices, ultimately driving success through effective data modelling and the alignment of business language with technological capabilities.
Webinar Details:
Title: Data Modeling – Just the Facts – A Demonstration
Date: 04 November 2024
Presenter: Marco Wobben
Meetup Group: INs & OUTs of Data Modelling
Write-up Author: Howard Diesel
Contents
Data and Information Management
Demo: A Use Case on Student Apprenticeships
A New Project in a Digital Application
Information Modelling and Database Structures
Data Semantics
Constraints in Data Structures
Integration of ChatGPT and Data Warehouse Builder
International Language Modelling and Translation in Software Development
Temporal Data Tracking and Communication in Data Management
Understanding and Meeting Data Requirements
Business Strategy and Data Management
Data Modelling and Business Language in Technology
Data and Information Management
Marco Wobben opens the webinar with the evolution of information sharing. He mentions the progression from printed materials to electronic media and that this transformation is relatively recent in the grand timeline of history. Today, we face an overwhelming amount of data that can be transient and difficult to navigate, akin to fish being unaware of their water.
While organisations often provide data, what individuals truly seek is meaningful information, which is complex to structure and manage. This challenge was emphasised by a professor who dedicated decades to teaching how to critically engage with information, resonating with René Descartes' notion that "I doubt, therefore I am," highlighting the importance of questioning in understanding. In the Dutch legal system, for example, citizens can access comprehensive legal articles online, demonstrating a practical method for making information accessible and understandable.
Regulations at both government and enterprise levels often involve complex jargon and limited definitions, particularly regarding the term "student," which typically refers solely to individuals attending school. The challenge lies in the inconsistent ways schools and universities manage their student data, which is influenced by various vendors and contextual business needs.
To effectively translate legal articles and regulatory requirements into actionable data, it's essential to understand the underlying data needs rather than just the data structures. This requires clear communication in natural language, allowing for the formalisation of that communication into structured information. This process enables the modelling of facts and the development of IT solutions that enhance communication within educational environments.

Figure 1 "Recently" Electronic Information

Figure 2 "Present" Eternal Data & Flighty Information

Figure 3 "Data is Everywhere" Information is not

Figure 4 "What we Need" Information

Figure 5 "The Information" How to Organise that

Figure 6 "The Information" How to 'Think' That?

Figure 7 "I Doubt" therefor I Think, therefor I Am

Figure 8 "Wetten.Overheid.NL" Law and Regulations
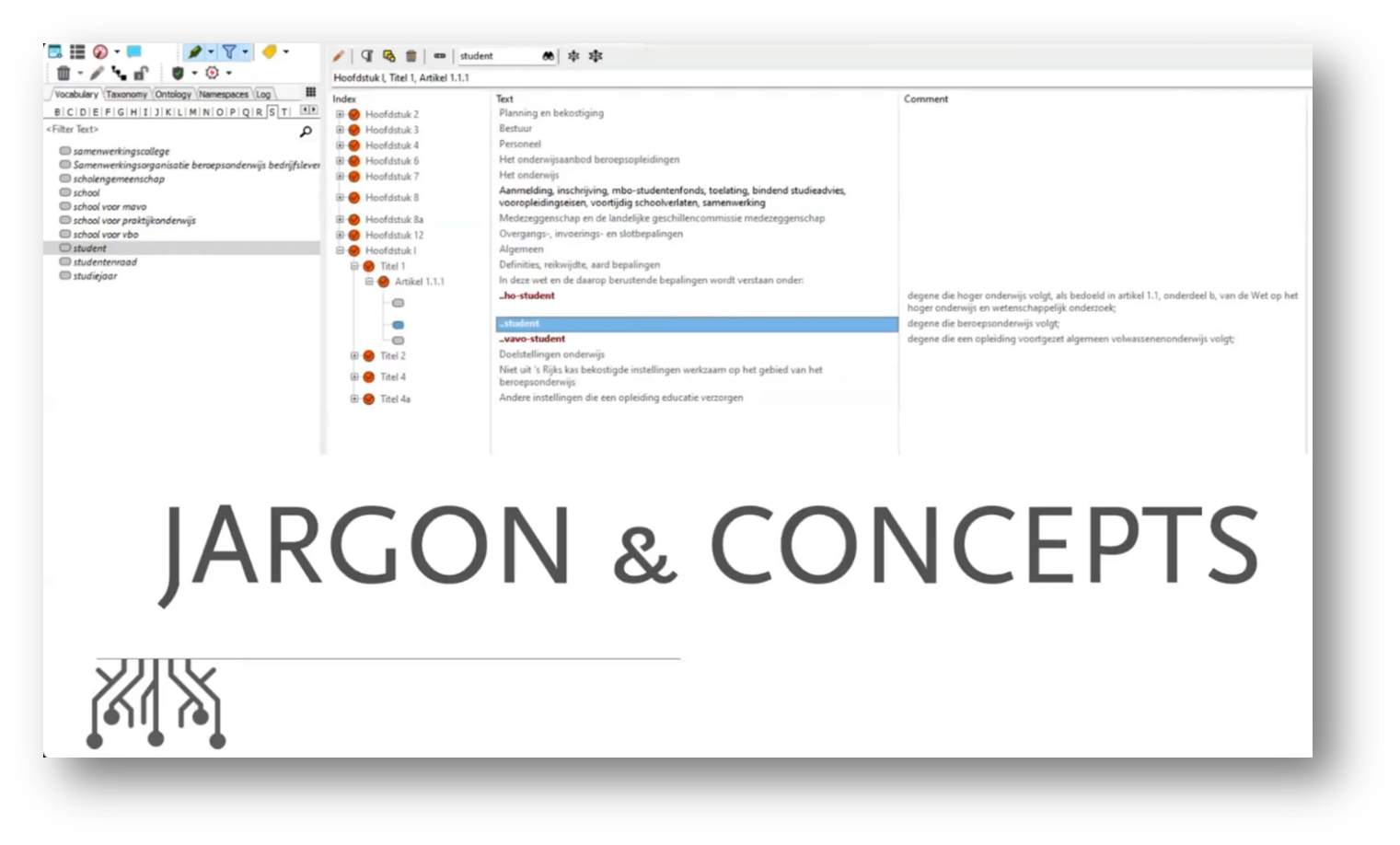
Figure 9 "Jargon & Concepts"
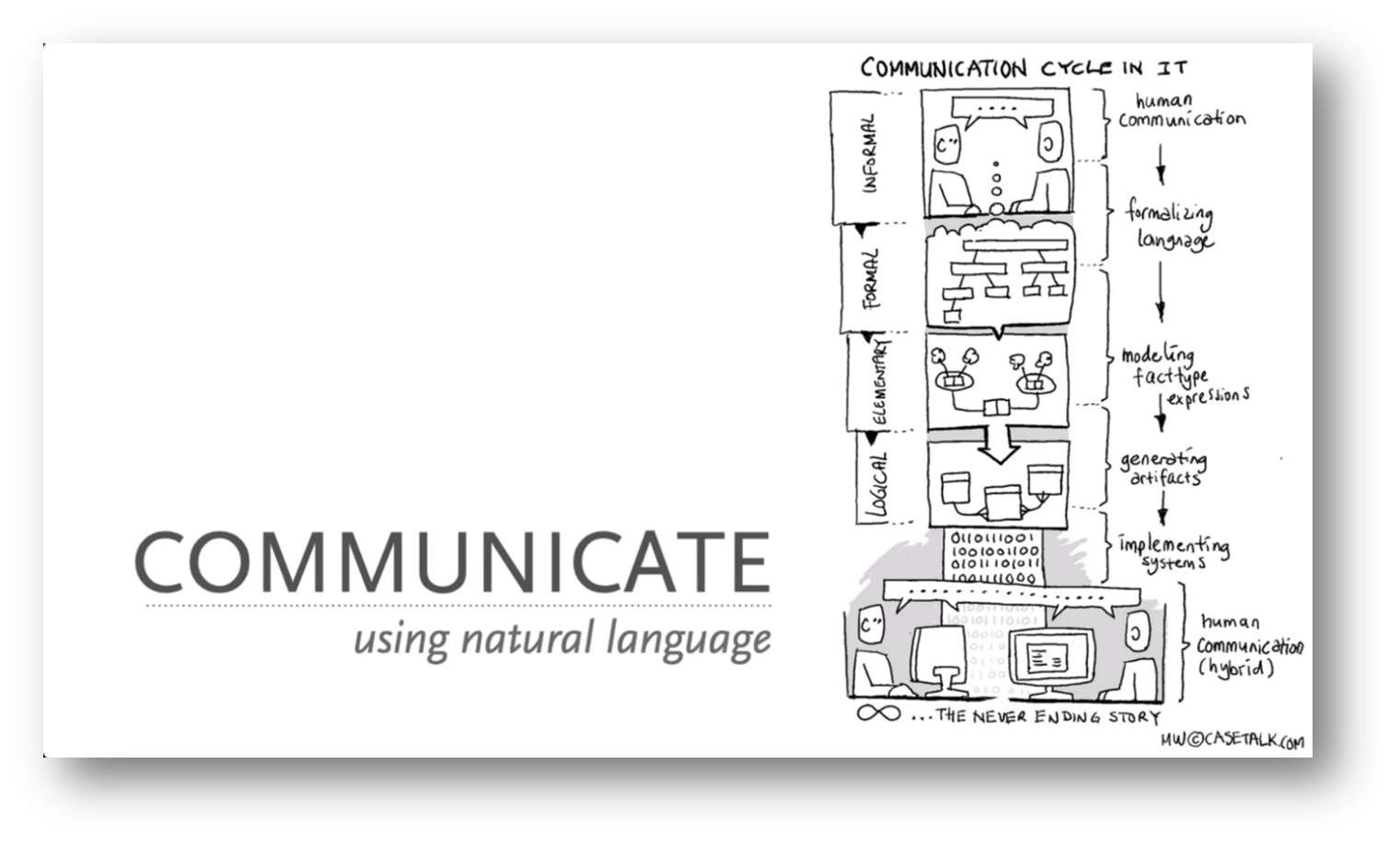
Figure 10 "Communicate" Using Natural Language
Demo: A Use Case on Student Apprenticeships
Marco shares that he will present a use case involving student apprenticeships that includes fictional data for simplicity and clarity. The demo involves a system where students fill out registration forms to express their preferences for various apprenticeships, which are then assigned based on available opportunities that include project descriptions and locations.
AI integration is a part of this process, Marco notes that it is important to emphasise that human involvement remains essential. The tools used will enhance efficiency and may alter job responsibilities, but they will not eliminate the need for human oversight and participation in apprenticeship management.

Figure 11 Contextual Data

Figure 12 "A Demo" by Marco
A New Project in a Digital Application
Marco demonstrated the functionality of CaseTalk, an application designed for project development. He then highlighted its user interface with multiple panels for efficient navigation. Starting a new project, Marco outlines the setup, including a project panel with files and a vocabulary section. Using a concrete example, he introduces a fact statement about a student, “Marco Wobben,” who resides in Utrecht, demonstrating how to qualify and label components of the statement. Marco then identified parts of the text to create a structured representation of the "city of residence," linking the student to their location, effectively illustrating the relationship between the two elements.
The demo focused on the completion of a qualification level and the representation of a student's information in a nested structure. Marco emphasizes that both the student's first name and surname are straightforward values without hidden information.
There is a clarification on the distinction between the name of a city (Utrecht) and its representation in a database, underscoring the necessity of storing it as a city name rather than just "city." Marco then notes potential name clashes when modelling different entities like students and customers, suggesting that using specific identifiers could help mitigate such issues.

Figure 13 CaseTalk Welcome Page
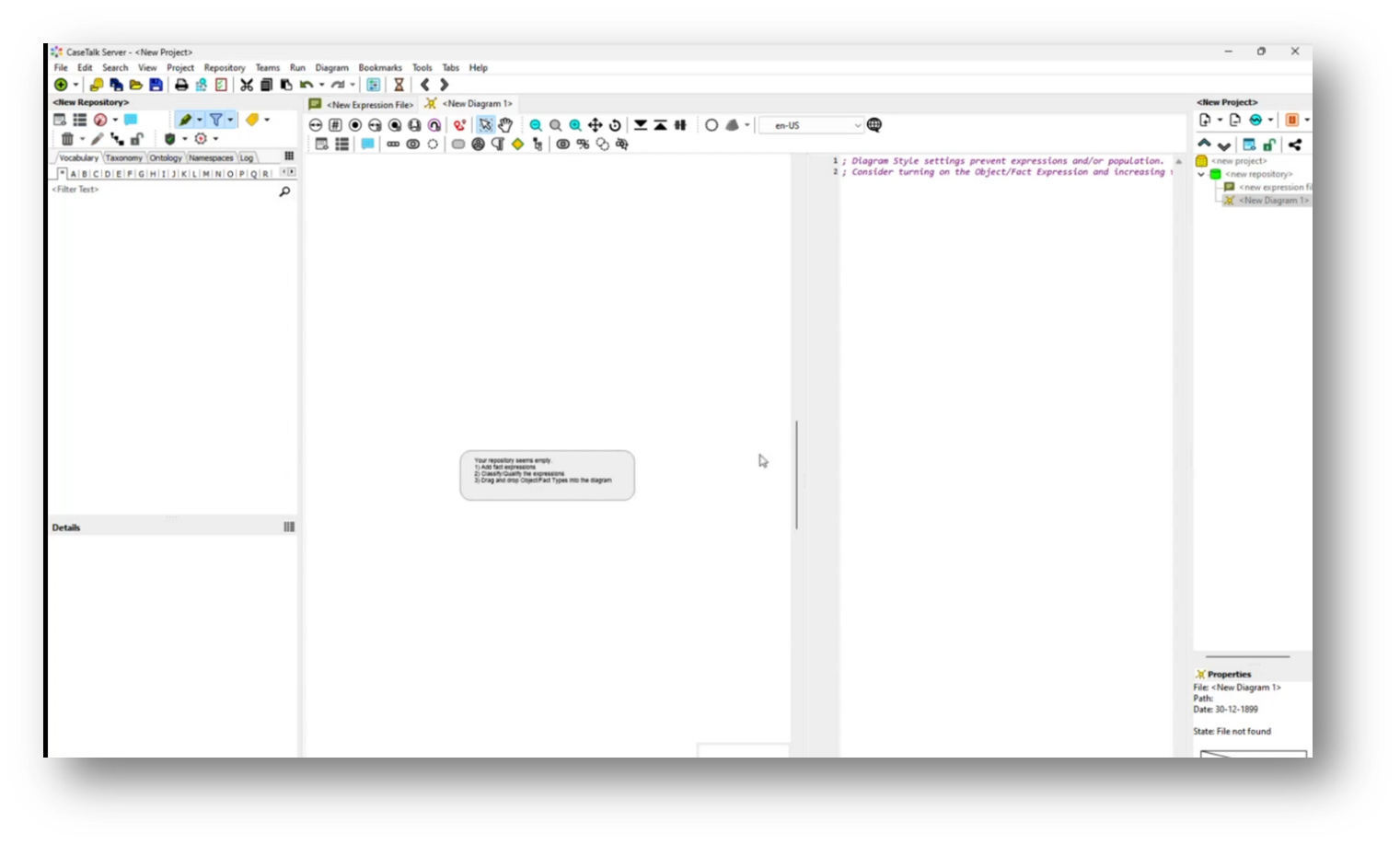
Figure 14 New Project
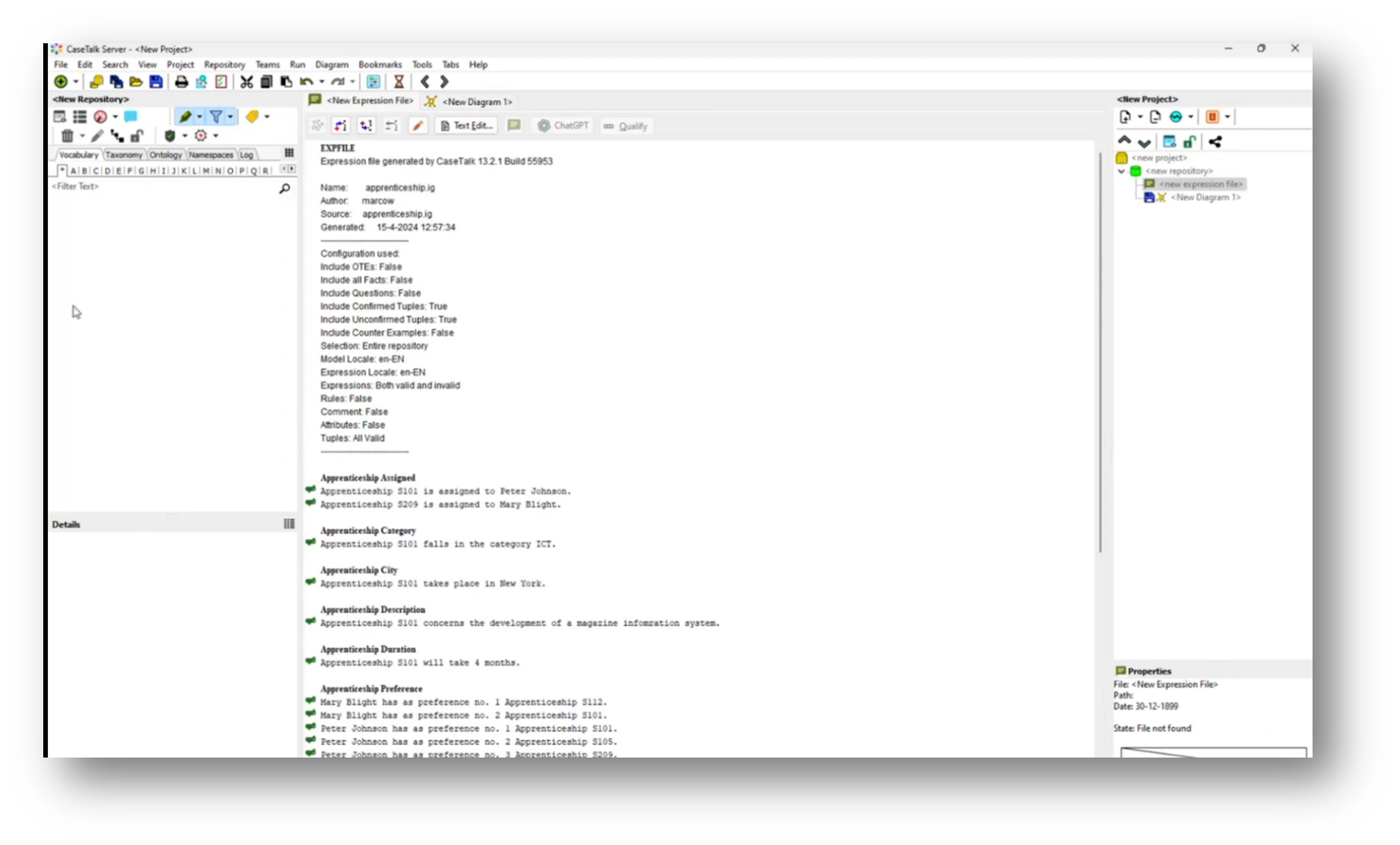
Figure 15 New Expression File
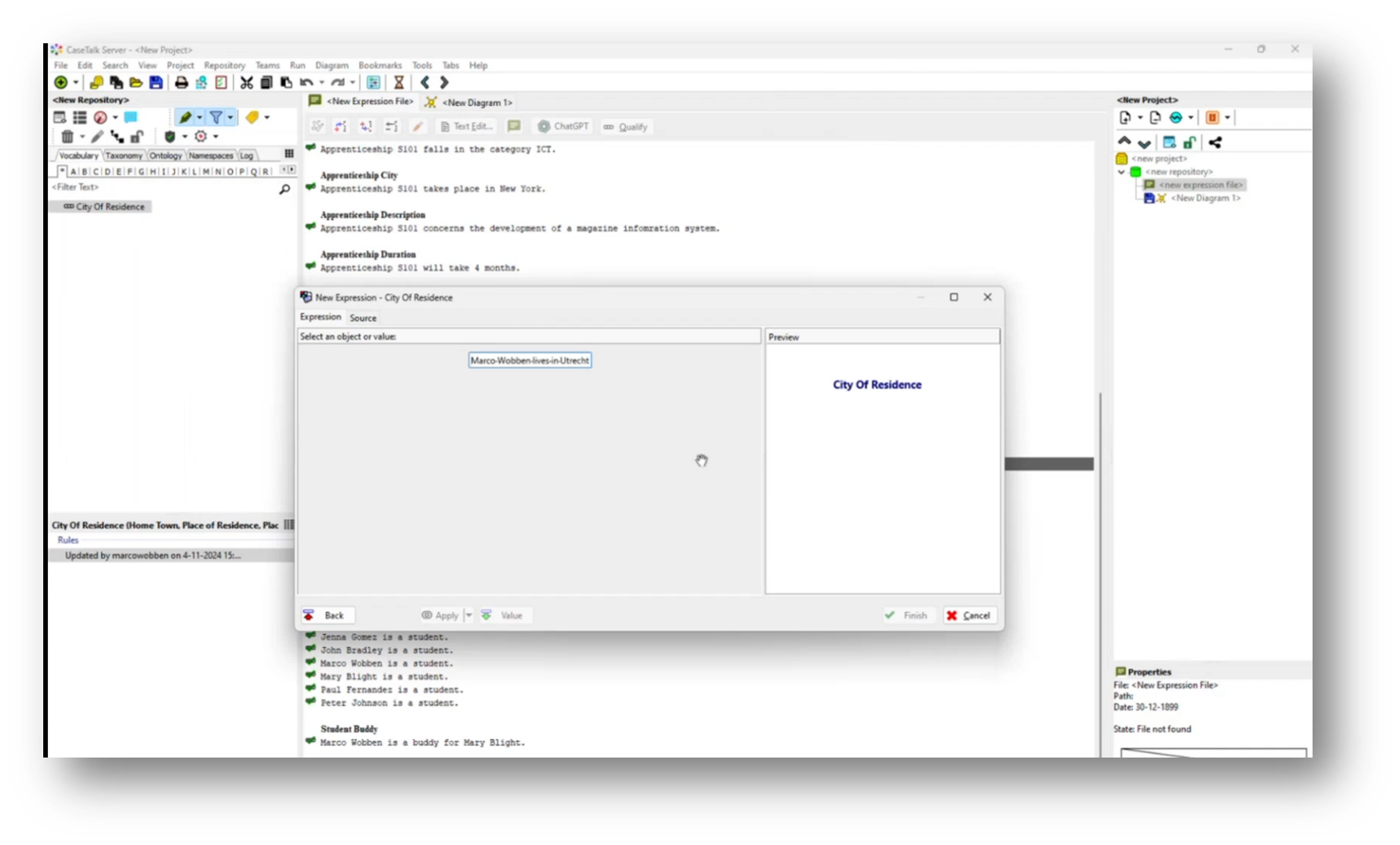
Figure 16 "New Expression" Box with Selected Expression
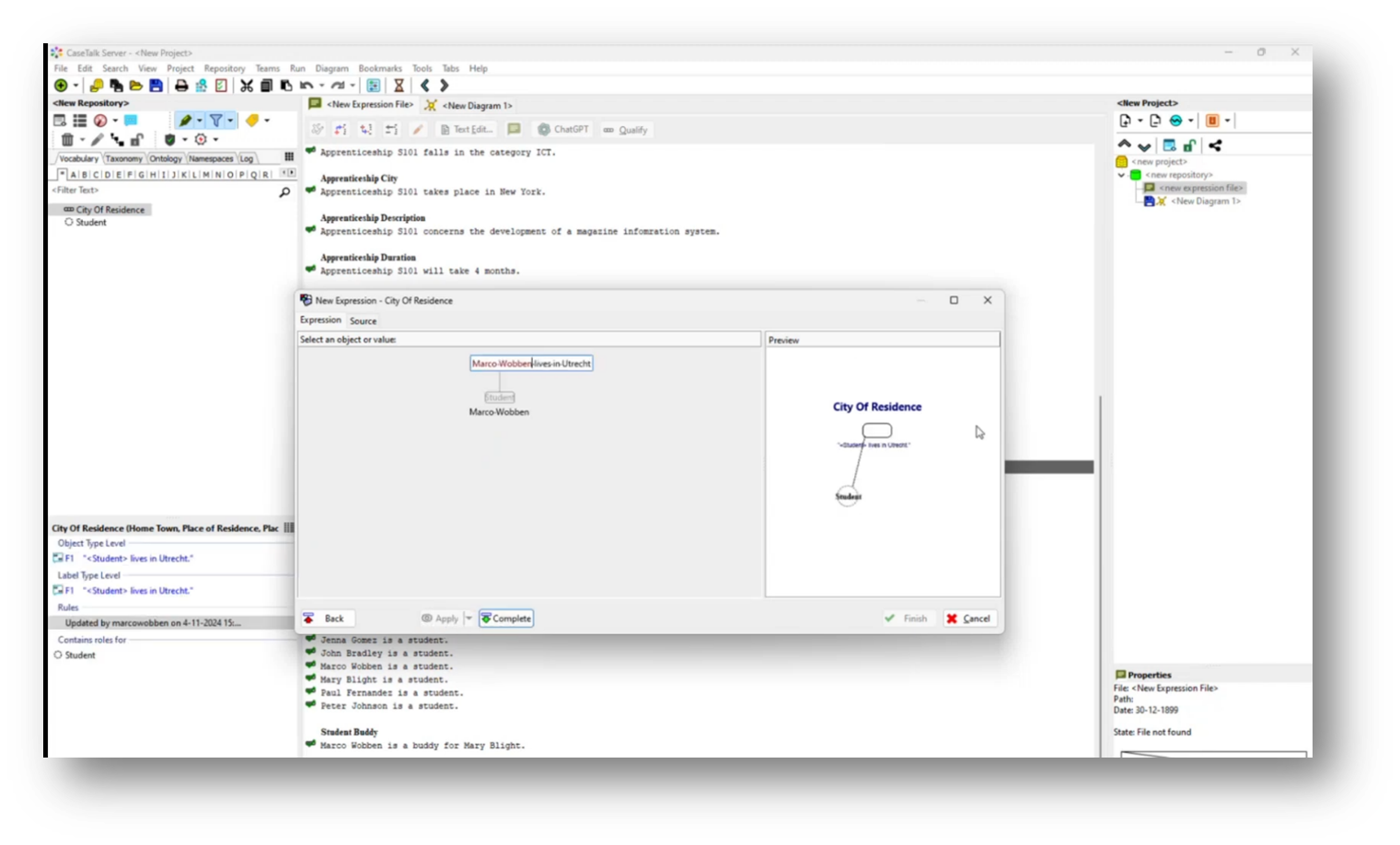
Figure 17 Select Object "Student = Marco Wobben"

Figure 18 Select Object "City = Utrecht"
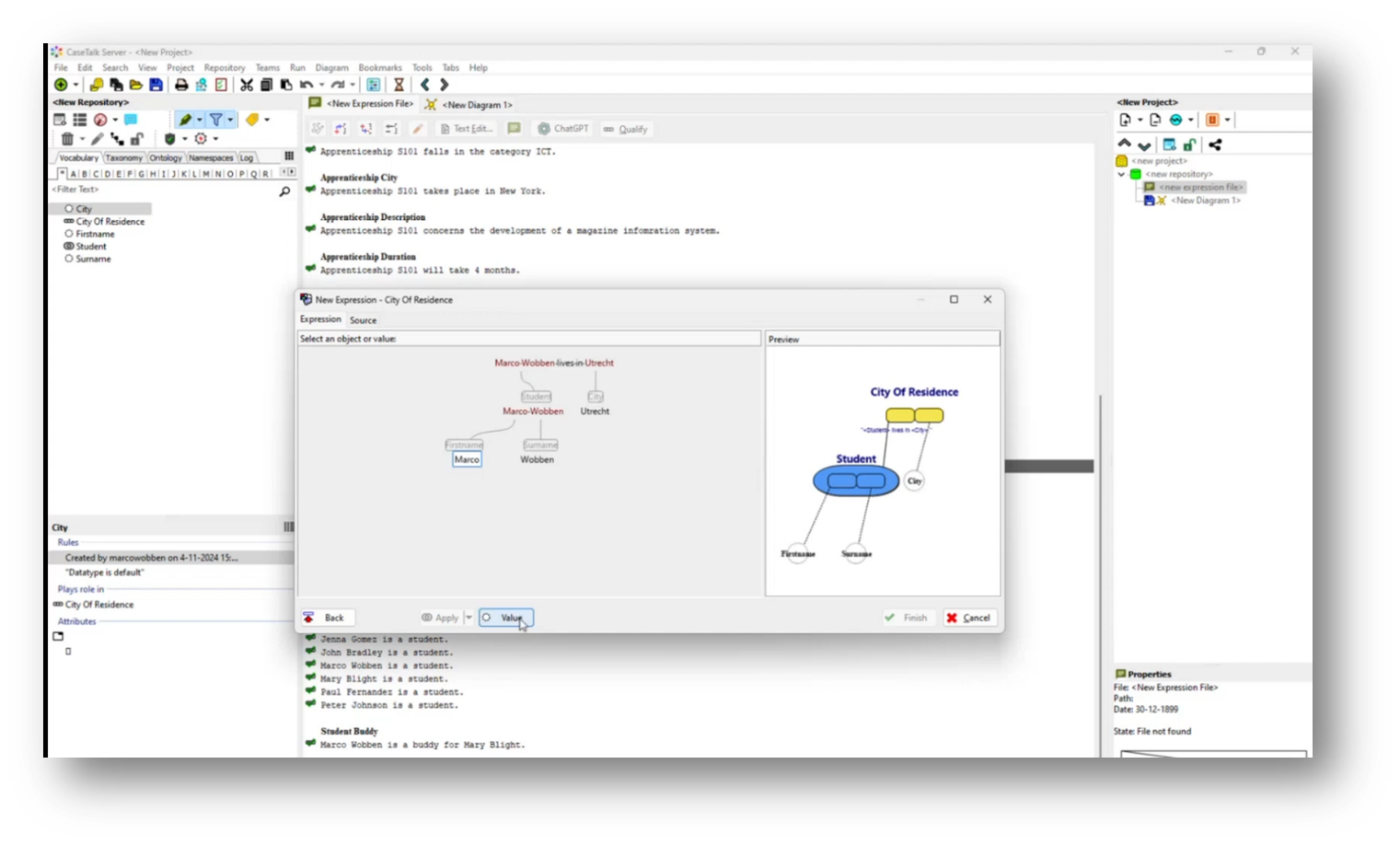
Figure 19 Splitting Student into "Firstname" and "Surname"
Information Modelling and Database Structures
Marco goes on to discuss the process of information modelling, specifically focusing on how to visualize and structure data related to student residency in a city. He describes the creation of a vocabulary that includes entities such as "Student" with attributes like first name and surname, and "City" with city name. By utilizing UML class diagrams, the relationship between students and their city of residence is depicted, emphasizing that each student can only belong to one city, thus transforming the relationship into an attribute within the Student entity.
Additionally, Marco highlights the distinction between UML modelling and normalized database structures, where the latter focuses on capturing data contextually rather than as separate entities, resulting in a simplified student table that identifies residences through linked attributes.
Marco then moves on to organizing data related to apprenticeships and cities within a structured framework, emphasizing the relationships and connections between different entities. Specifically, an apprenticeship code (S101) is linked to a city (New York), demonstrating the many-to-many relationship between apprenticeships and cities. As the relational diagram evolves, it reveals the apprenticeship and student tables, reinforcing that while city names are vital, they currently derive relevance solely through these associations without a dedicated database for cities. The necessity of establishing a reference for city names is highlighted, indicating that detailed communication about cities can only occur through the apprenticeship and student data.
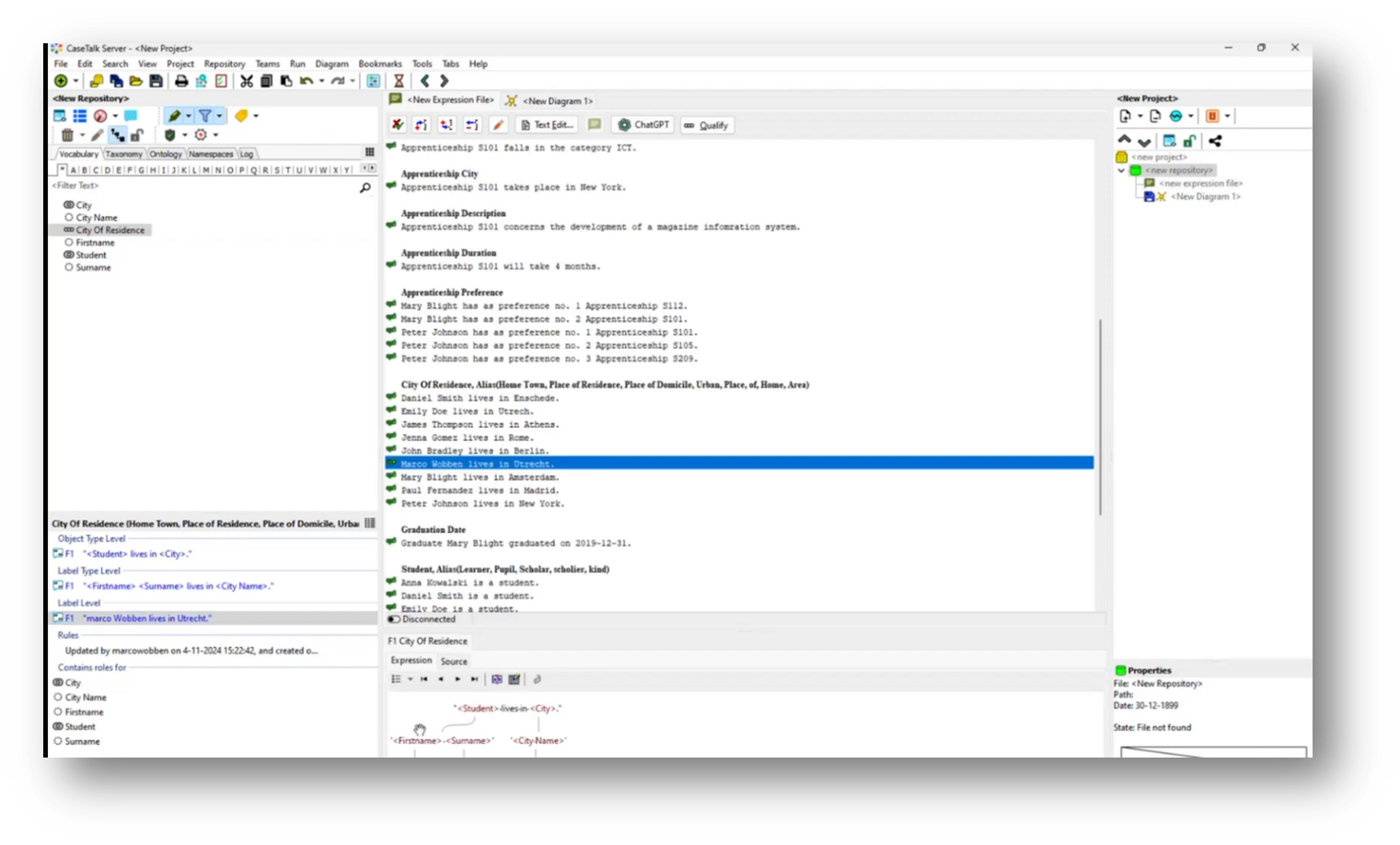
Figure 20 New Repository - Vocabulary
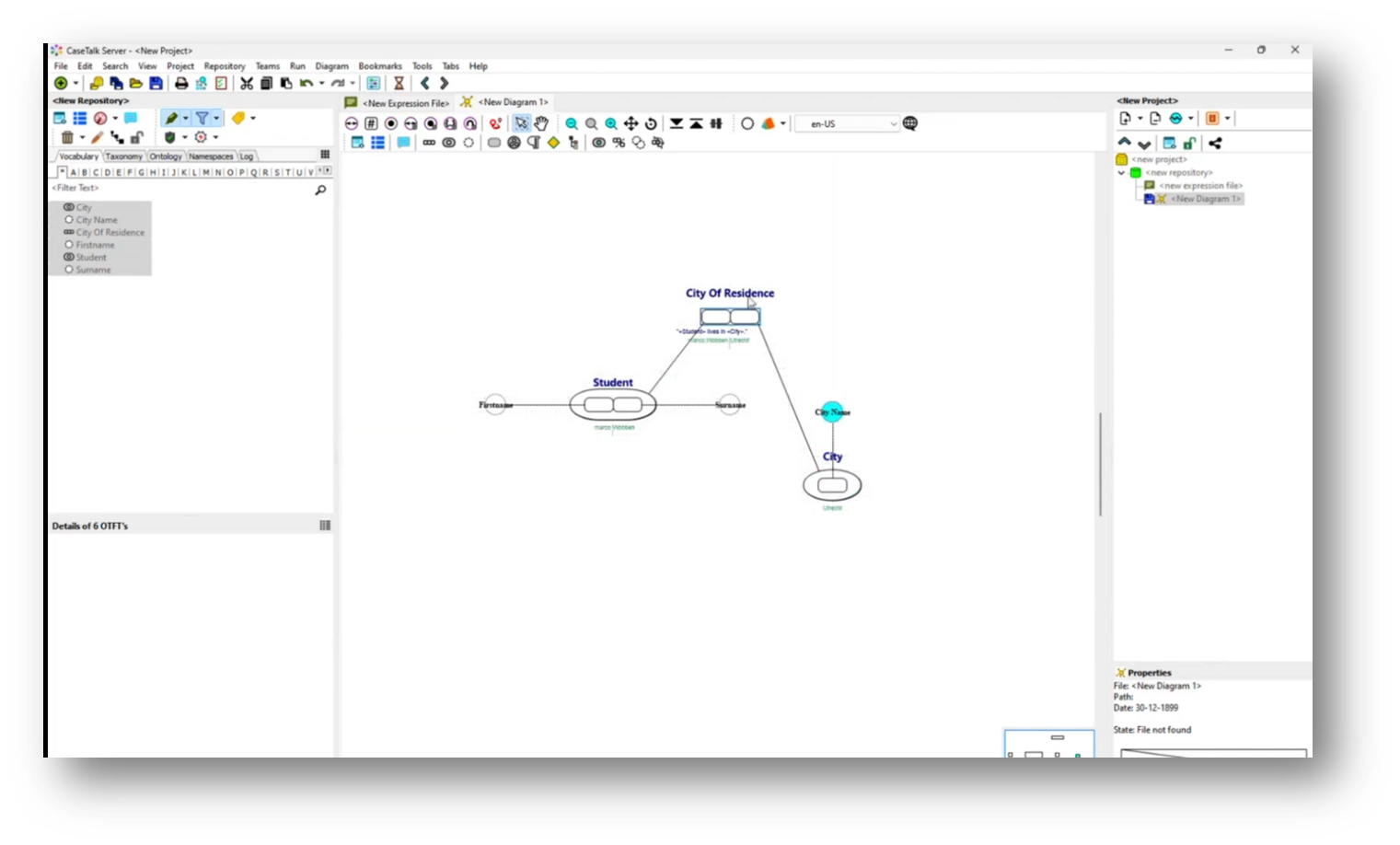
Figure 21 Diagram Generated from Repository
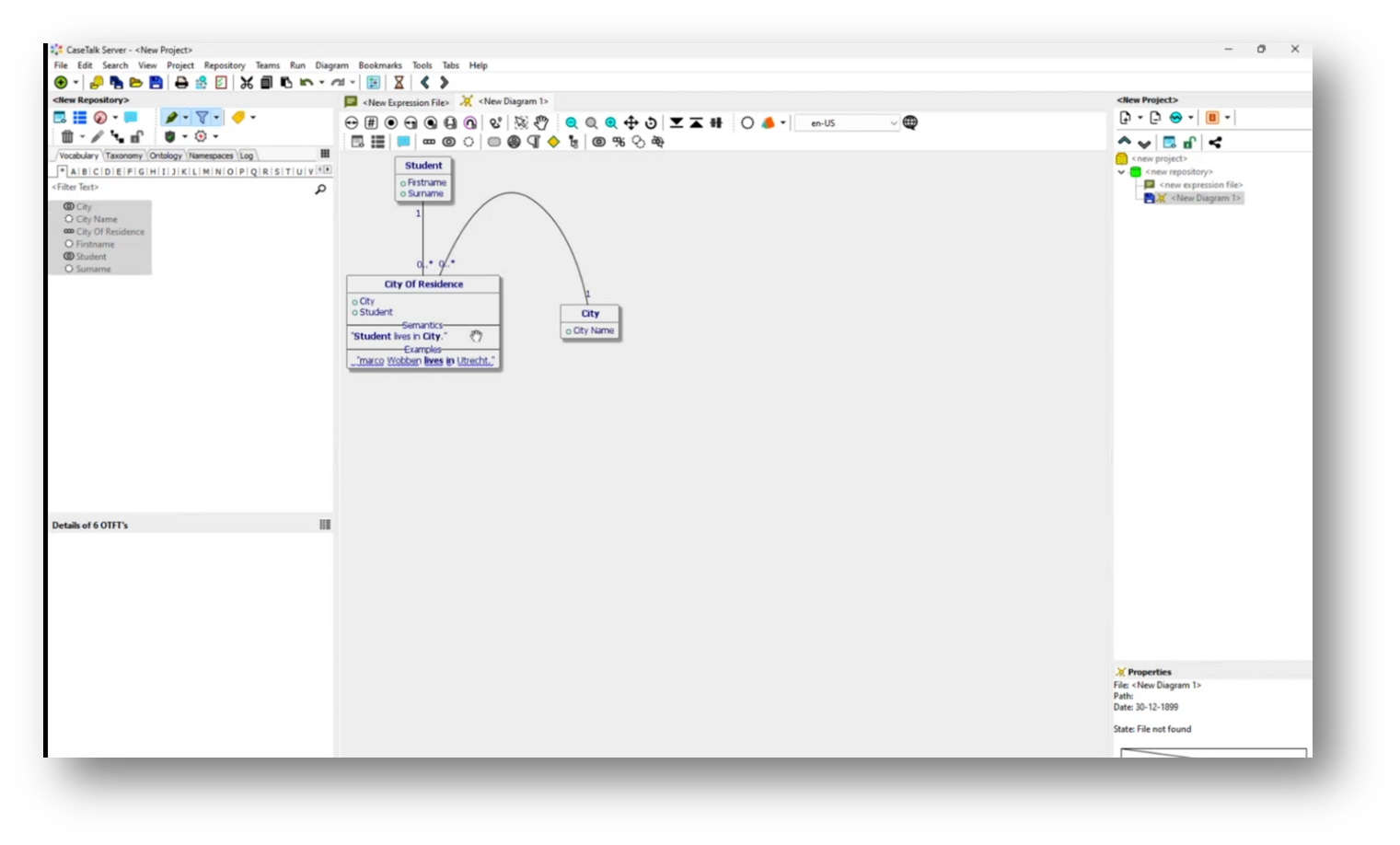
Figure 22 Relationships
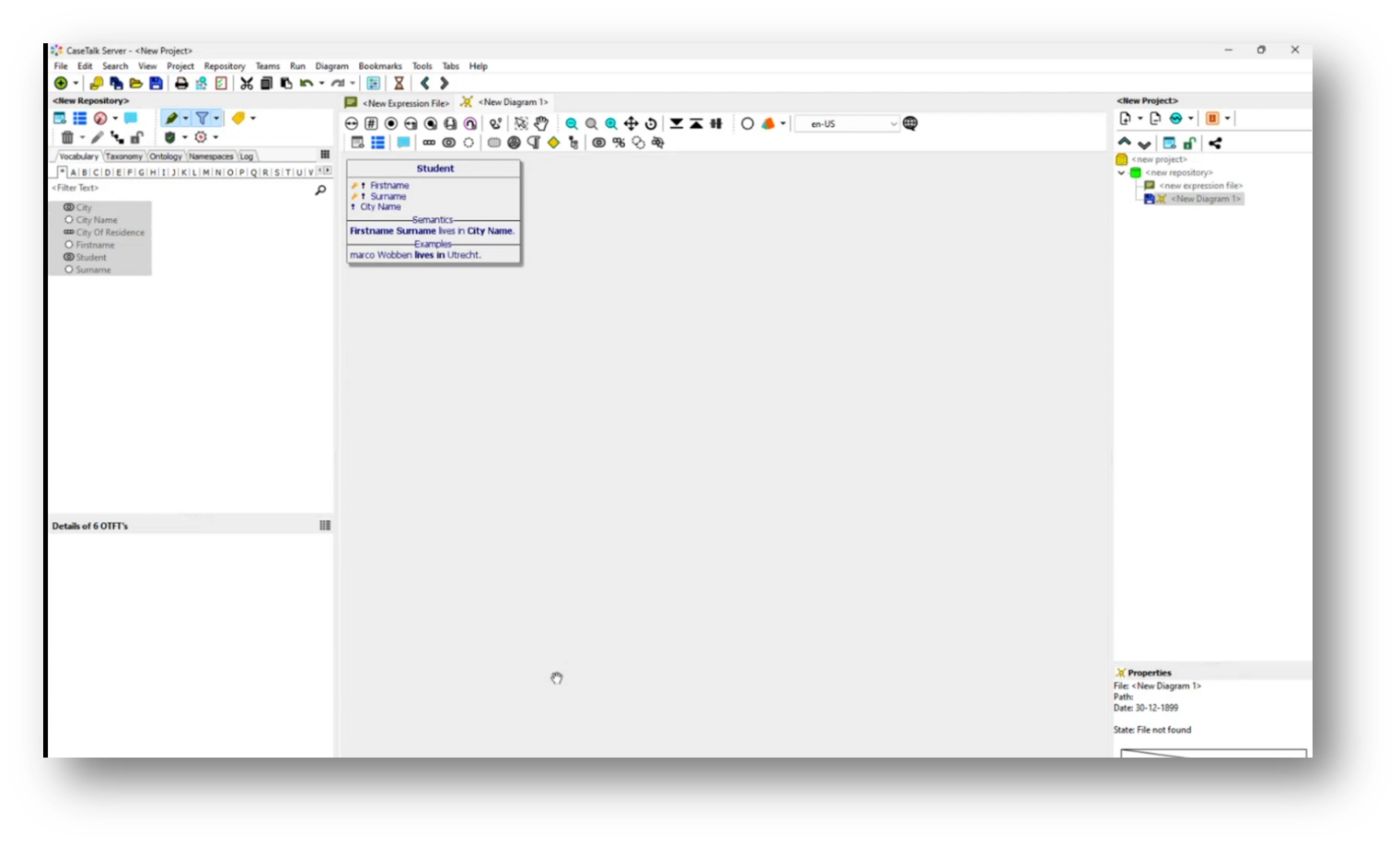
Figure 23 Object Student with Keys, Semantics and Examples

Figure 24 Defining Object "Apprenticeship"

Figure 25 Updated Diagram Contains "Apprenticeship City"
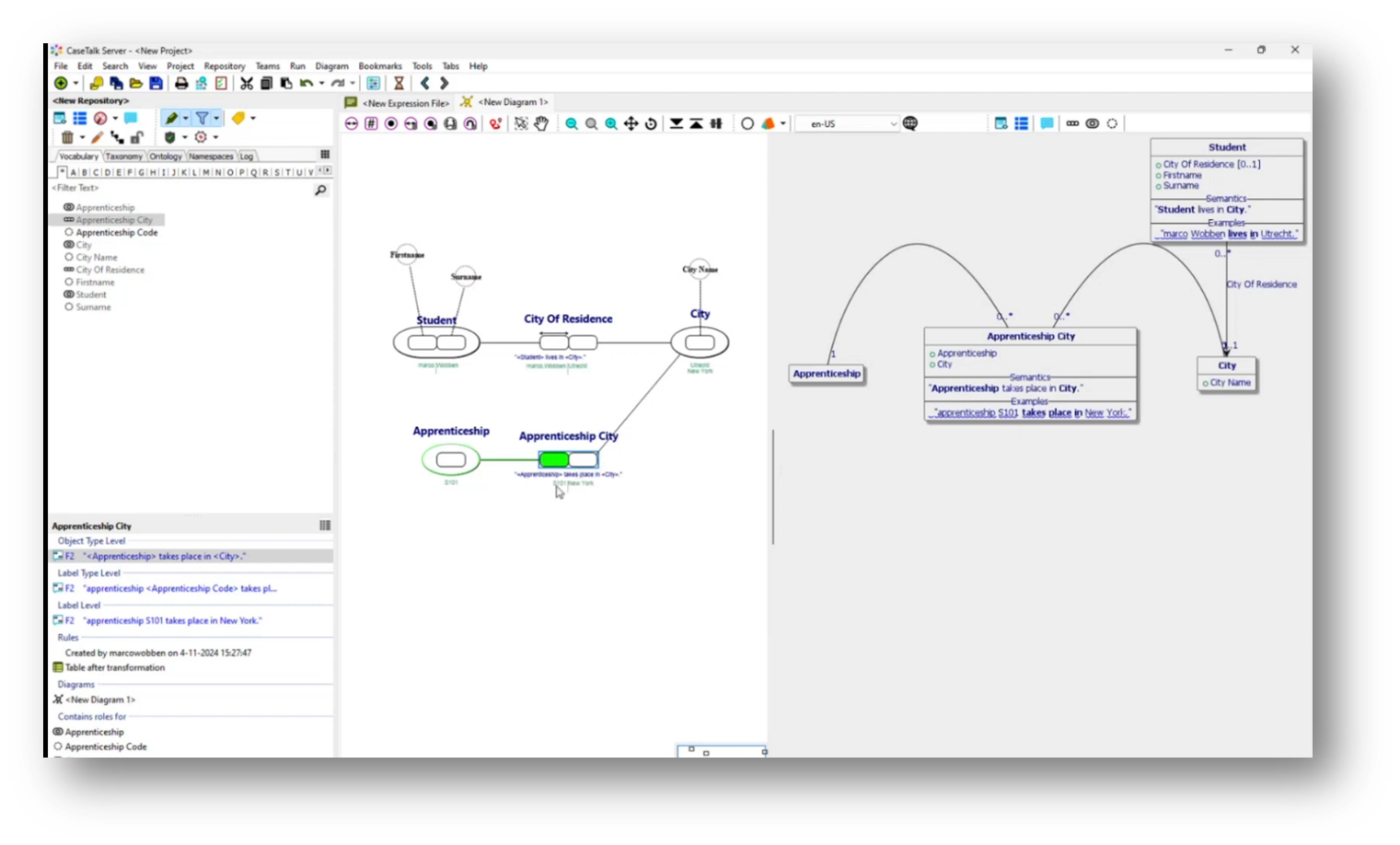
Figure 26 "Apprenticeship City" Present in Relational Model
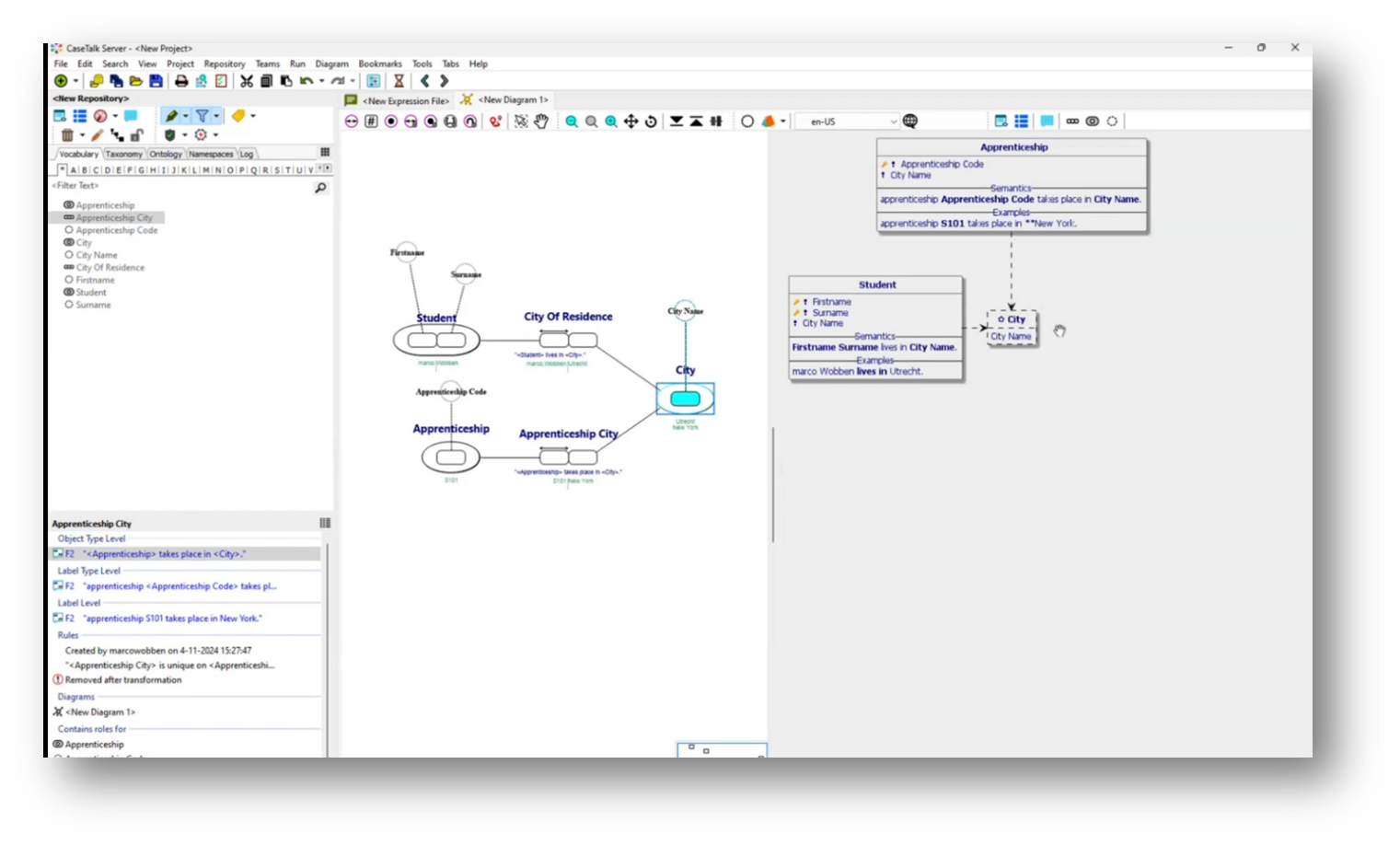
Figure 27 Focus on Object "City"
Data Semantics
A discussion starts on the naming conventions used in a database regarding the distinction between "city name" and its significance, specifically as it pertains to a student's "city of residence" versus other potential interpretations like "city of birth." Marco addresses the confusion arising from the term "normalized logical view," emphasising the need for clearer terminology to reflect the relationship to the student. It is acknowledged that while the current dataset is small enough to avoid naming clashes, features exist within the tool to enhance semantic clarity as data complexity increases. Overall, it's about ensuring that naming accurately conveys the data's context within the educational framework.
Marco then discusses information modelling with a focus on structuring data related to student residency in cities. He highlights the creation of a vocabulary that includes entities like "Student" and "City," detailing attributes such as names and residence relationships, which are depicted using UML class diagrams. Each student is linked to one city, transforming the relationship into an attribute within the Student entity. UML modelling is contrasted with normalised database structures, emphasising a more contextual approach to data organisation.
Further exploration occurs with the many-to-many relationship between apprenticeships and cities. Marco notes that this illustrates how apprenticeship codes are associated with specific cities, such as New York. This framework underscores the importance of city names while suggesting that their current relevance is derived mainly from these associations rather than having a dedicated database for cities.
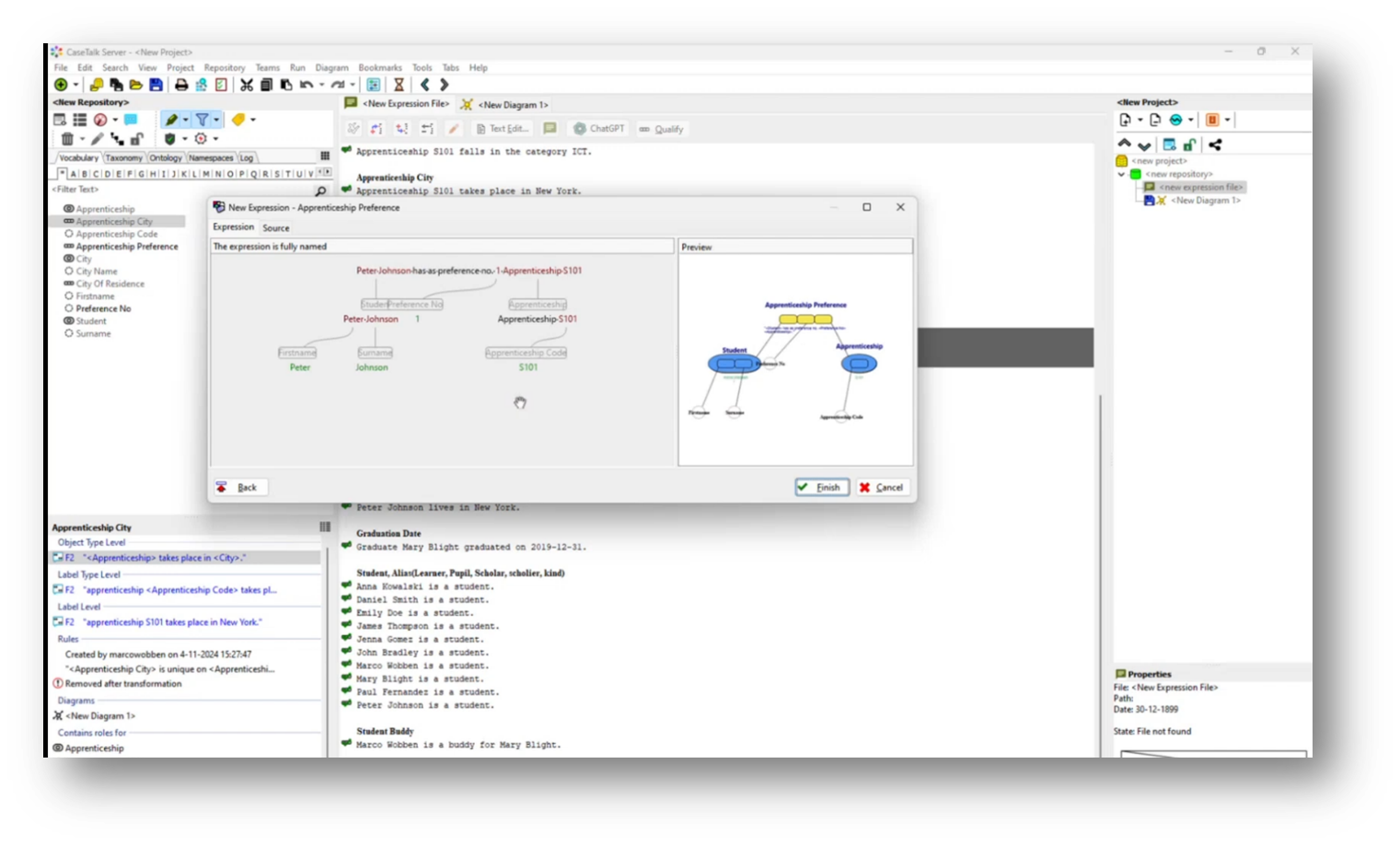
Figure 28 Dissecting the Fact Statement
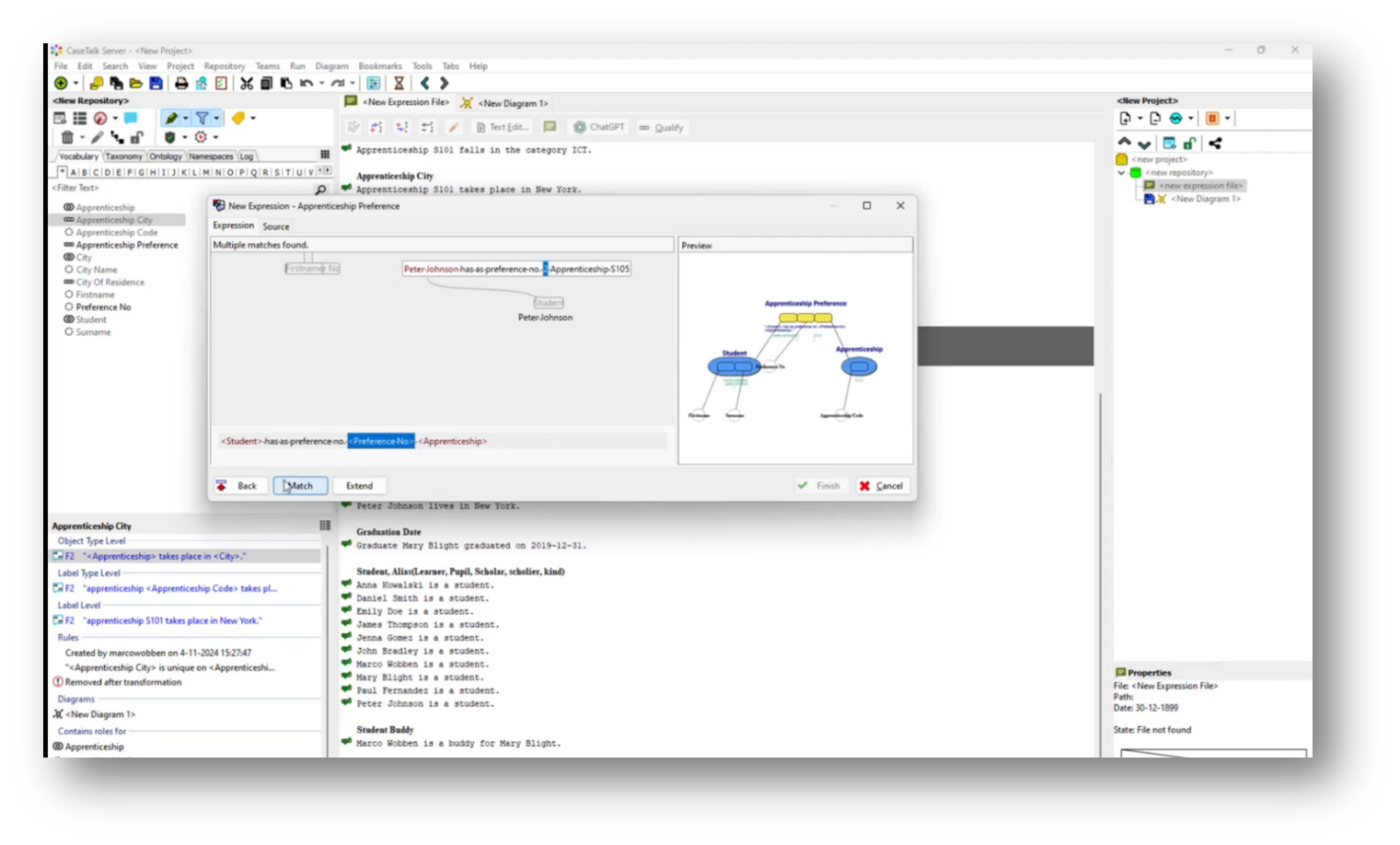
Figure 29 Adding Preference Number Value to Expression

Figure 30 "New Diagram" Expanded
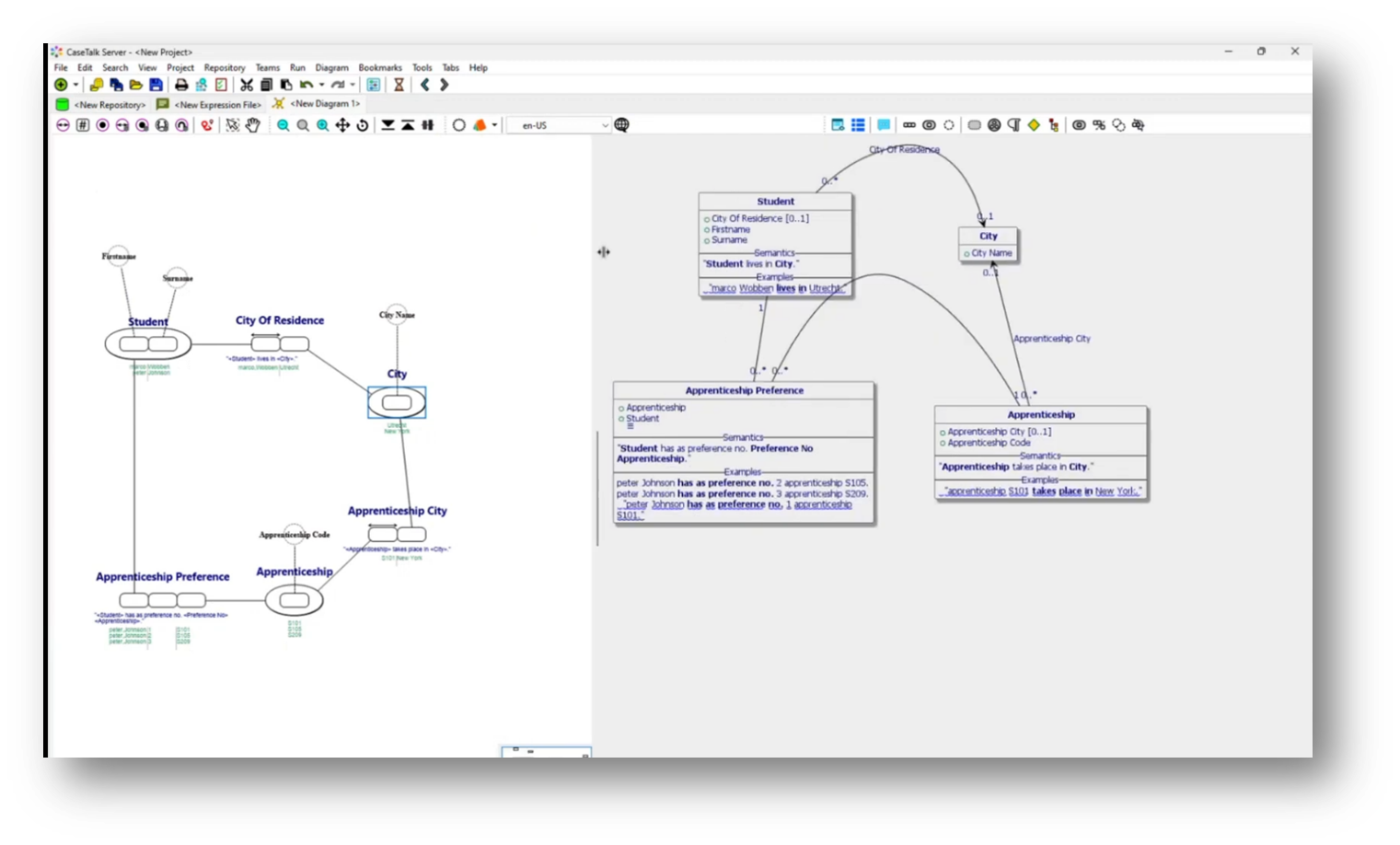
Figure 31 Relational Diagram Expanded
Constraints in Data Structures
The apprenticeship preferences system is designed to ensure unique ordinal choices for students, requiring each student to have distinct preferences for their apprenticeships. The wizard tool guides users through a series of questions to clarify these constraints, confirming that while one student can have the same first-choice apprenticeship as another, no two preferences can be the same for any student.
Upon updating the UML diagram, key attributes like student first name, surname, and apprenticeship become mandatory, establishing a clear structure with primary and foreign keys. Additionally, it captures the uniqueness of apprenticeships based on their codes and descriptions, showcasing how understanding business communication shapes the data architecture within the system.
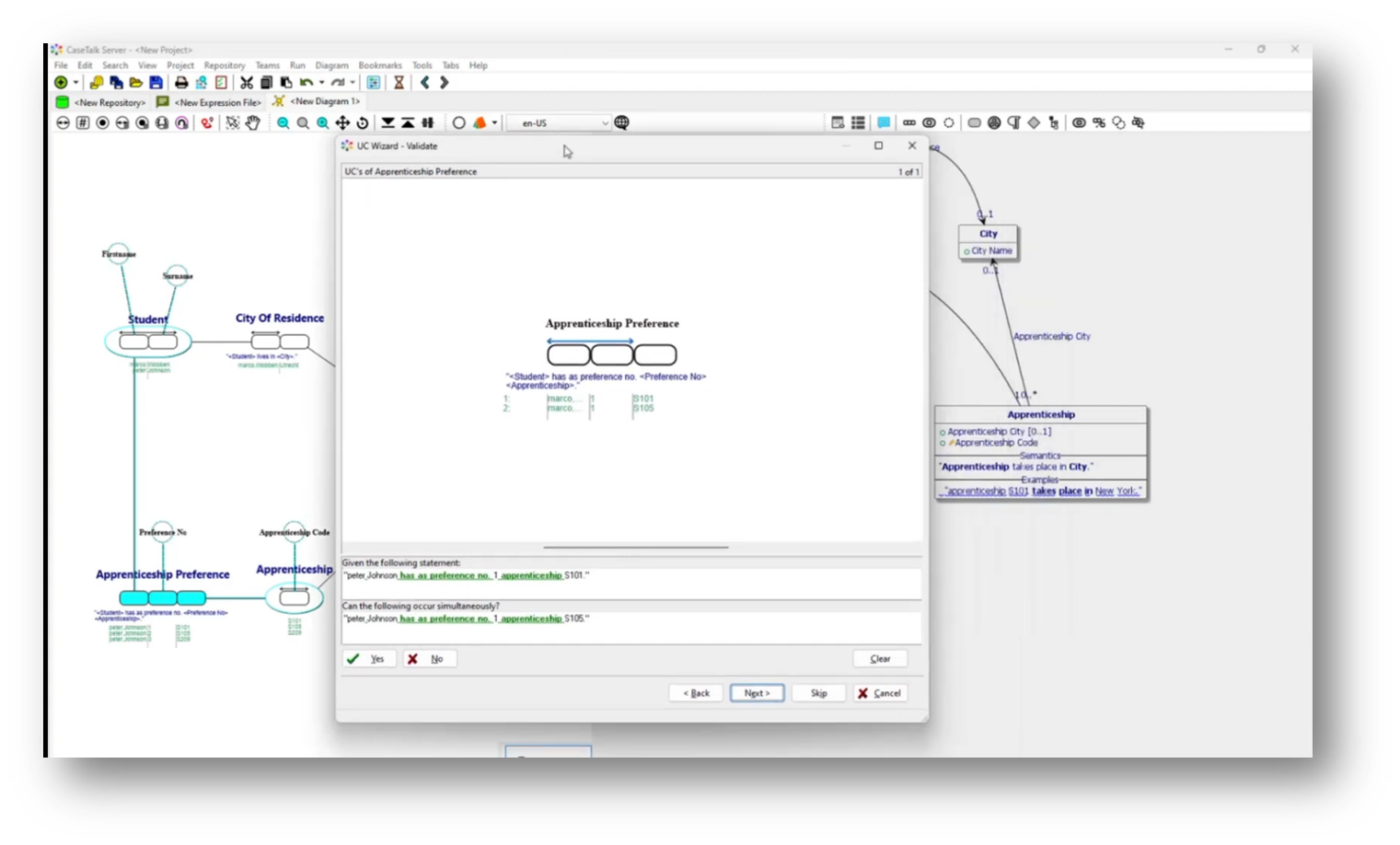
Figure 32 UC Wizard Testing Parameters

Figure 33 Defining Type, Appearance and Implementation of Object "City"
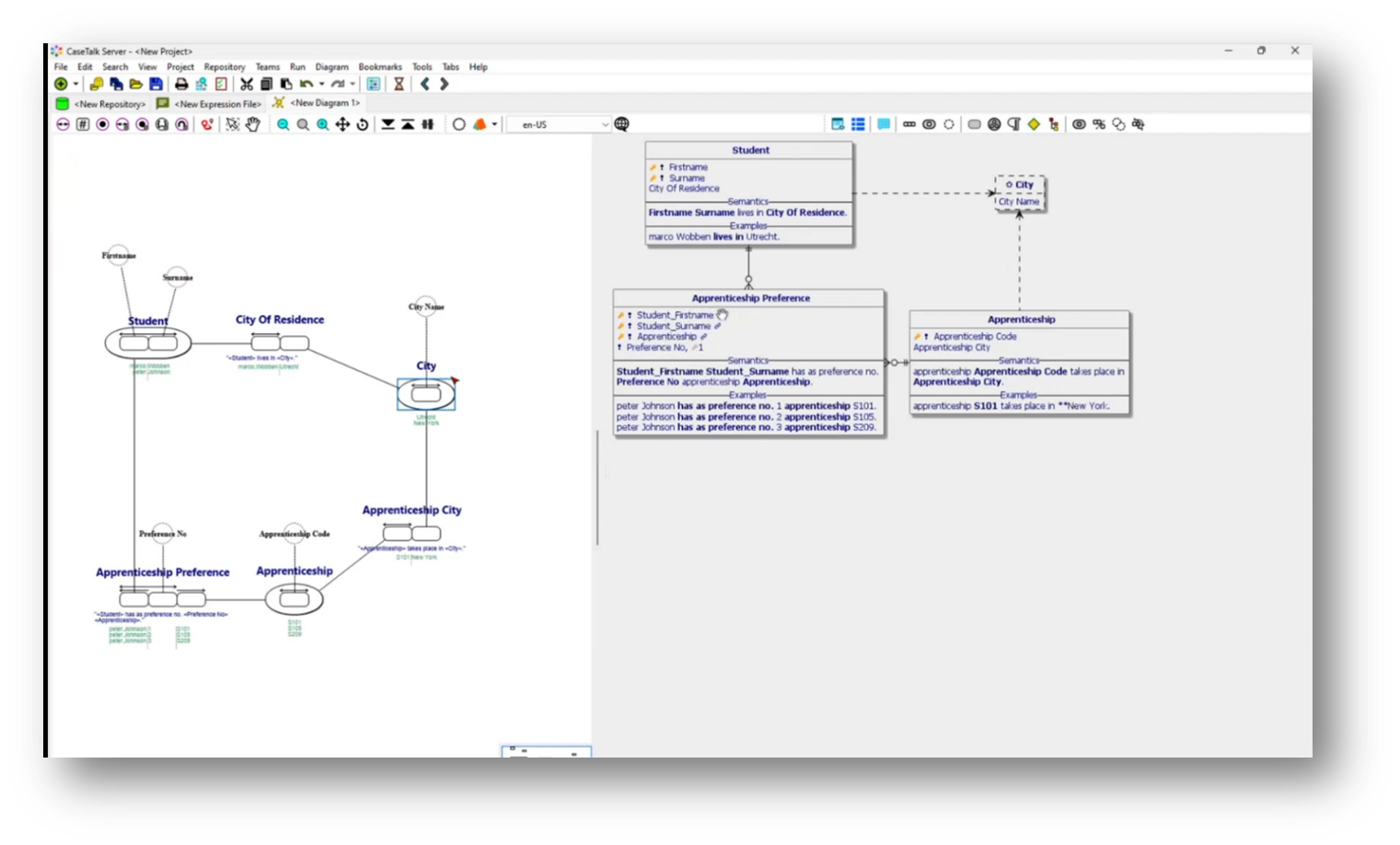
Figure 34 "New Diagram" Expanded Data Model
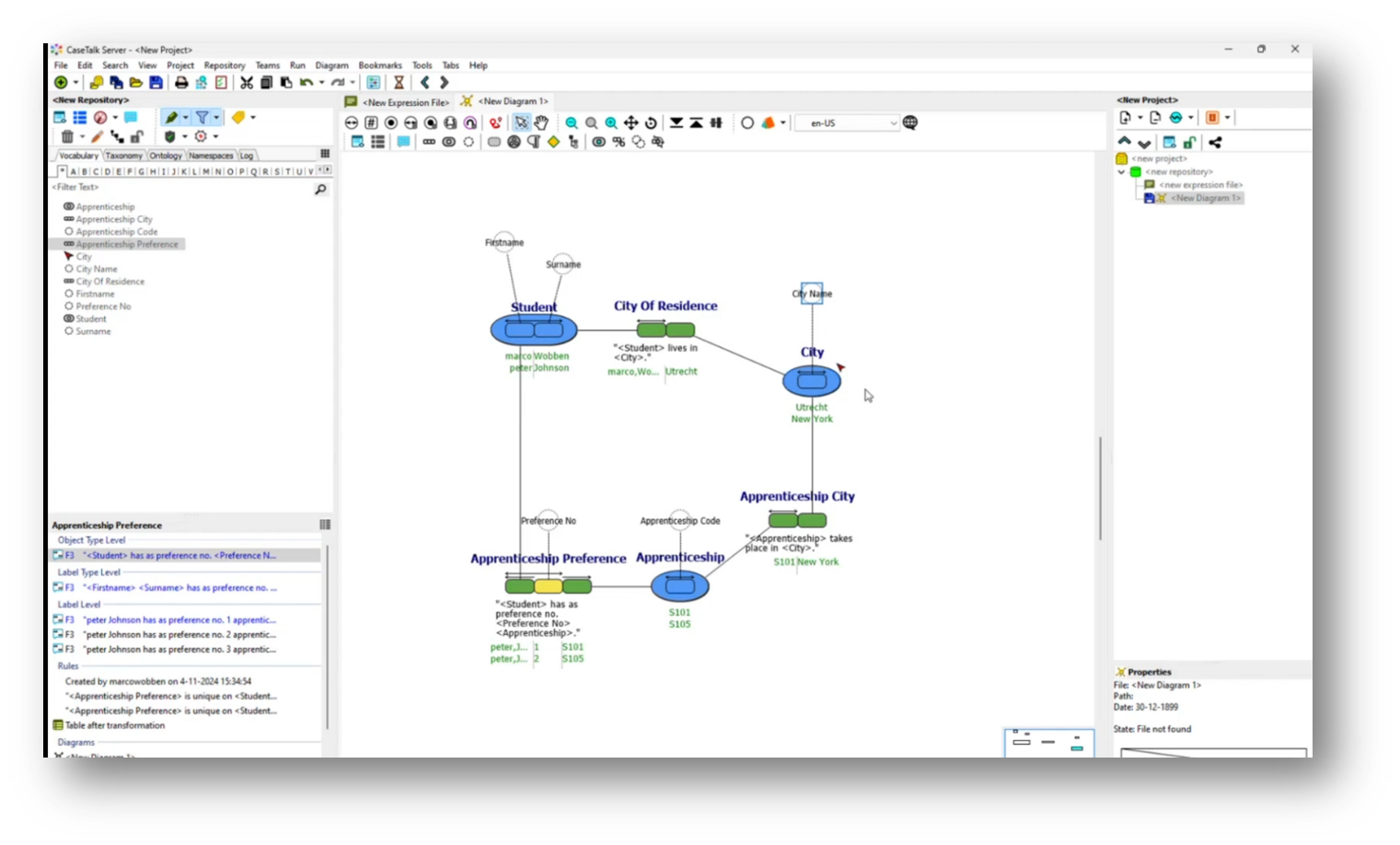
Figure 35 "New Diagram" in UML
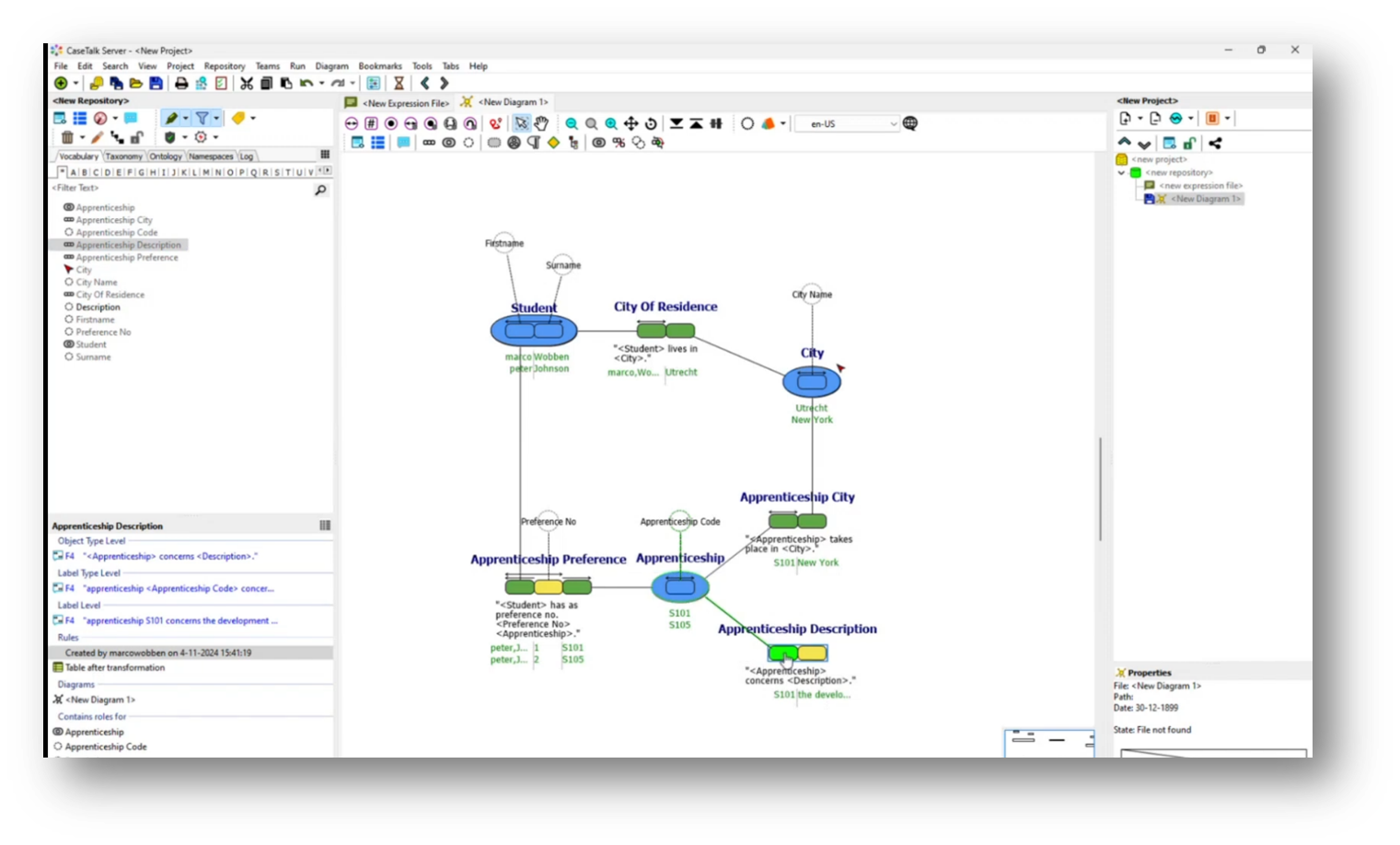
Figure 36 Adding "Apprenticeship Description"
Integration of ChatGPT and Data Warehouse Builder
A discussion starts on the integration of ChatGPT into educational tools, illustrating its ability to enrich student information with various details, including definitions and aliases. While the tool generally performs well, it occasionally generates inaccurate information, referred to as "hallucinations."
Marco emphasizes the importance of formulating questions for domain experts rather than making statements, enhancing collaboration and insight. Additionally, there are considerations for tweaking preference keys within diagrams to improve clarity and functionality, particularly in the context of data integration projects with clients using tools like data vault builders. Overall, the integration showcases both the potential and challenges of using AI to support educational frameworks.
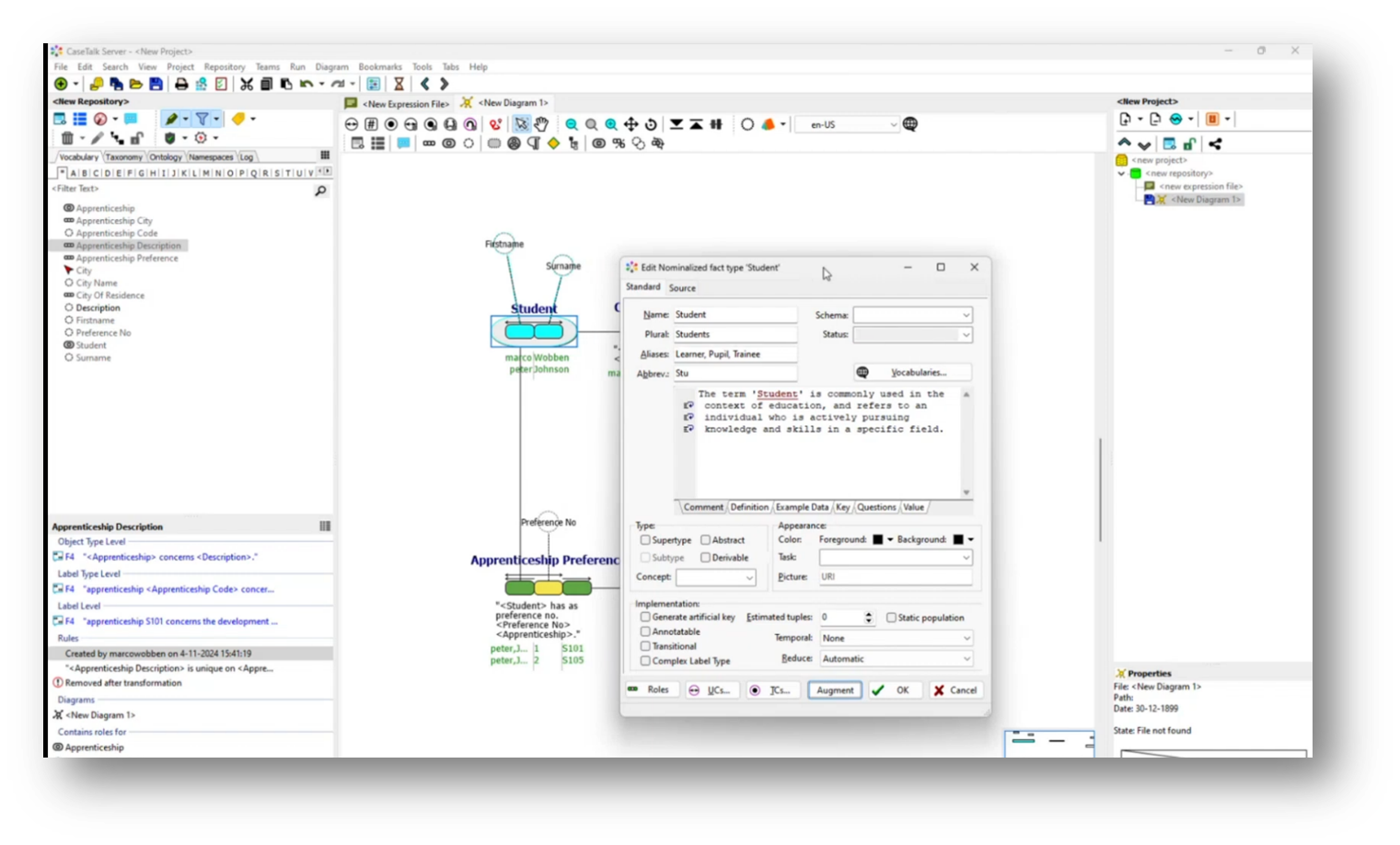
Figure 37 Using ChatGPT to Add Comments
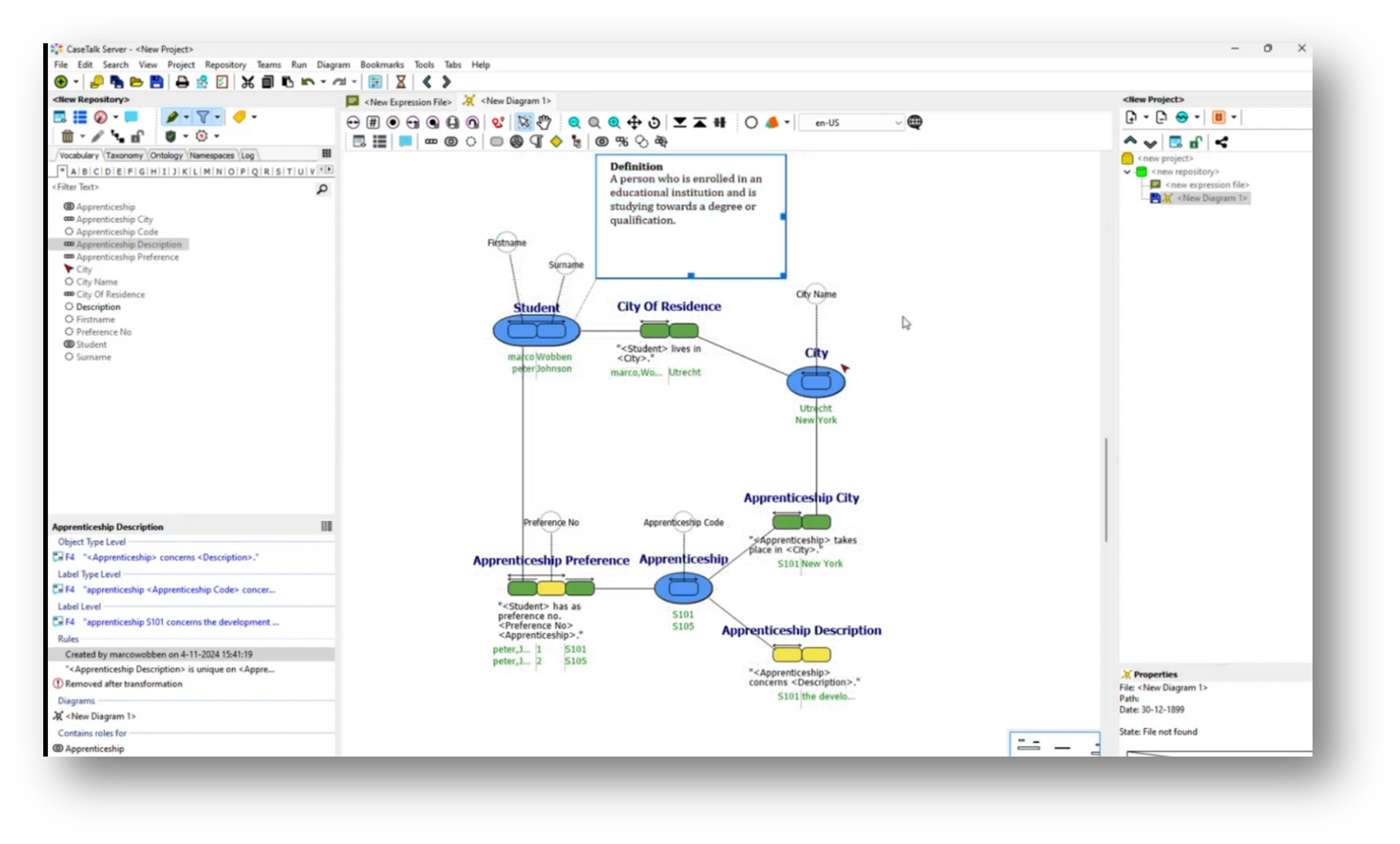
Figure 38 Adding a "Definition" Box
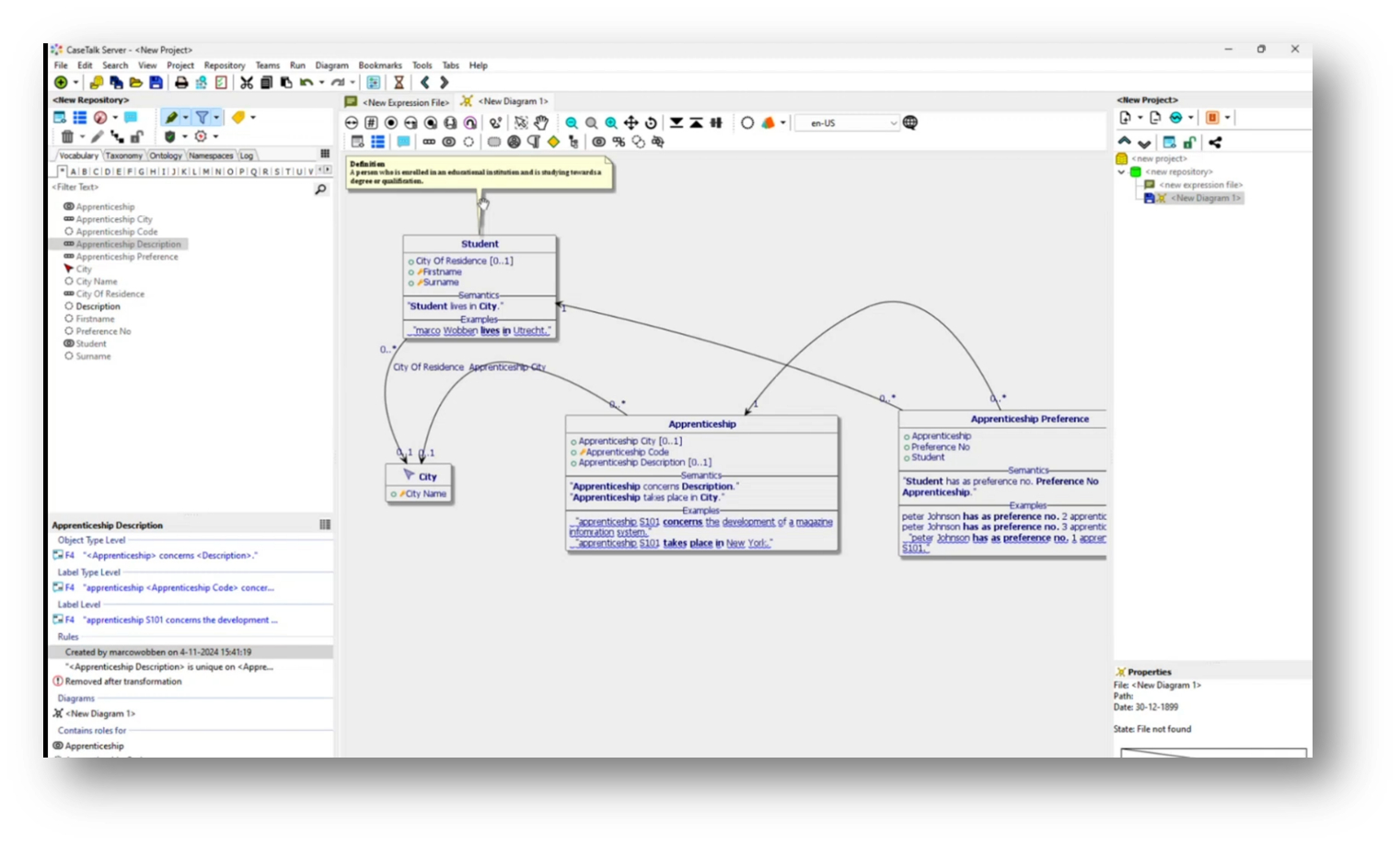
Figure 39 "Definition" present in Data Model
International Language Modelling and Translation in Software Development
In an international setting, particularly in the Netherlands, it can be challenging to navigate local regulations while accommodating multilingual teams. A new feature allows users to translate UML class diagrams into Spanish using deep-learning translation services, facilitating better communication with Spanish-speaking developers. Users can also leverage live data connections, such as from the Northwind database, to populate example populations dynamically without extensive manual input. This integration enhances usability by allowing teams to work in their preferred languages while accessing real-time information.
Marco goes on to highlight the extensive customization options available for diagram settings, including the integration of international reference tables like ISO city codes and country codes. He emphasises the ability to import data from Excel worksheets, even when direct access to a live production environment is restricted due to security concerns.
The presentation of metadata is also covered, noting that both live metadata and offline JSON files can be utilized. Additionally, users can enhance their information structure by mapping items like customer IDs to the corresponding production environment, creating technical dictionaries, and generating artefacts that incorporate both business and technical terminology.
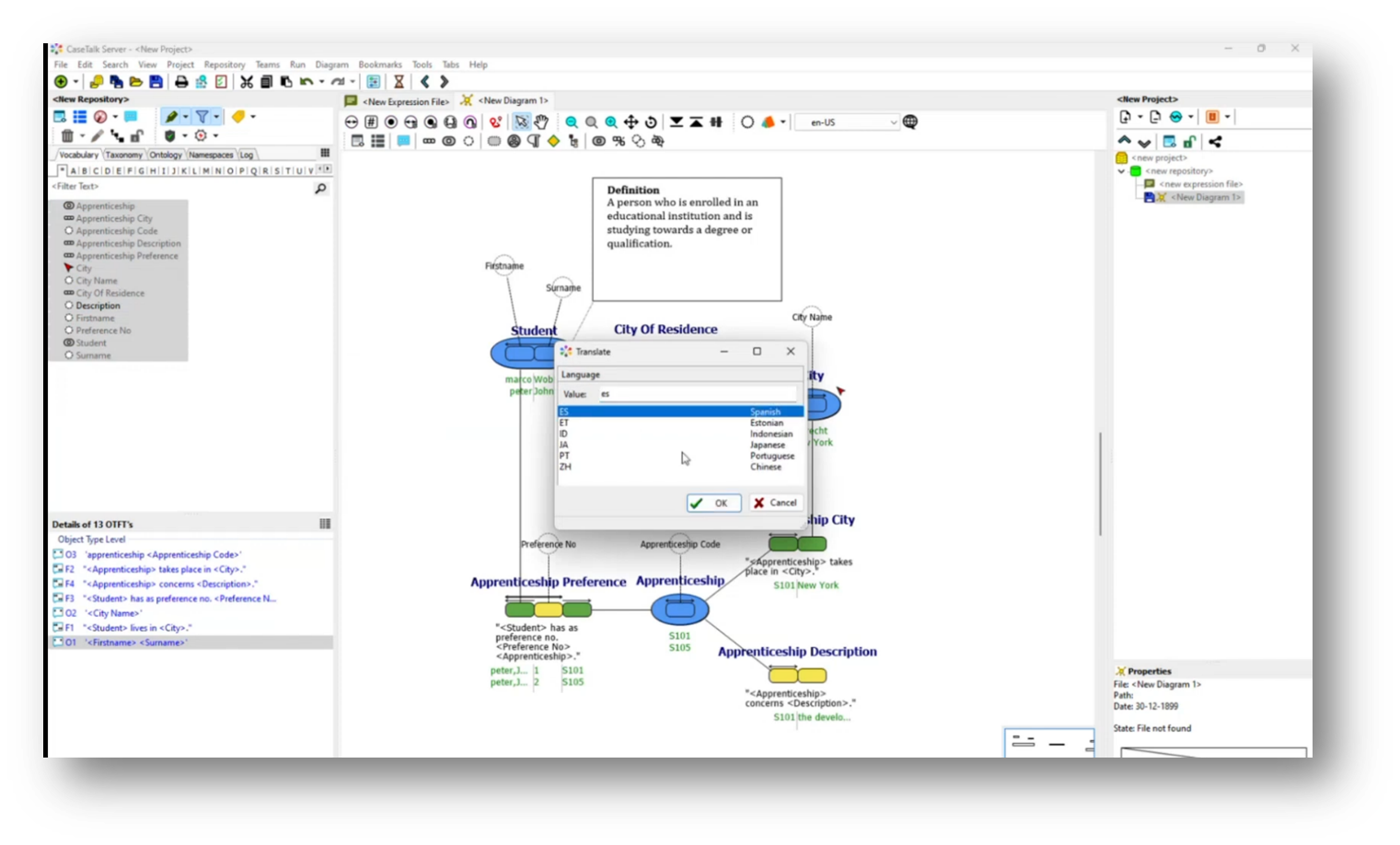
Figure 40 Choosing a Language to Translate the Model into
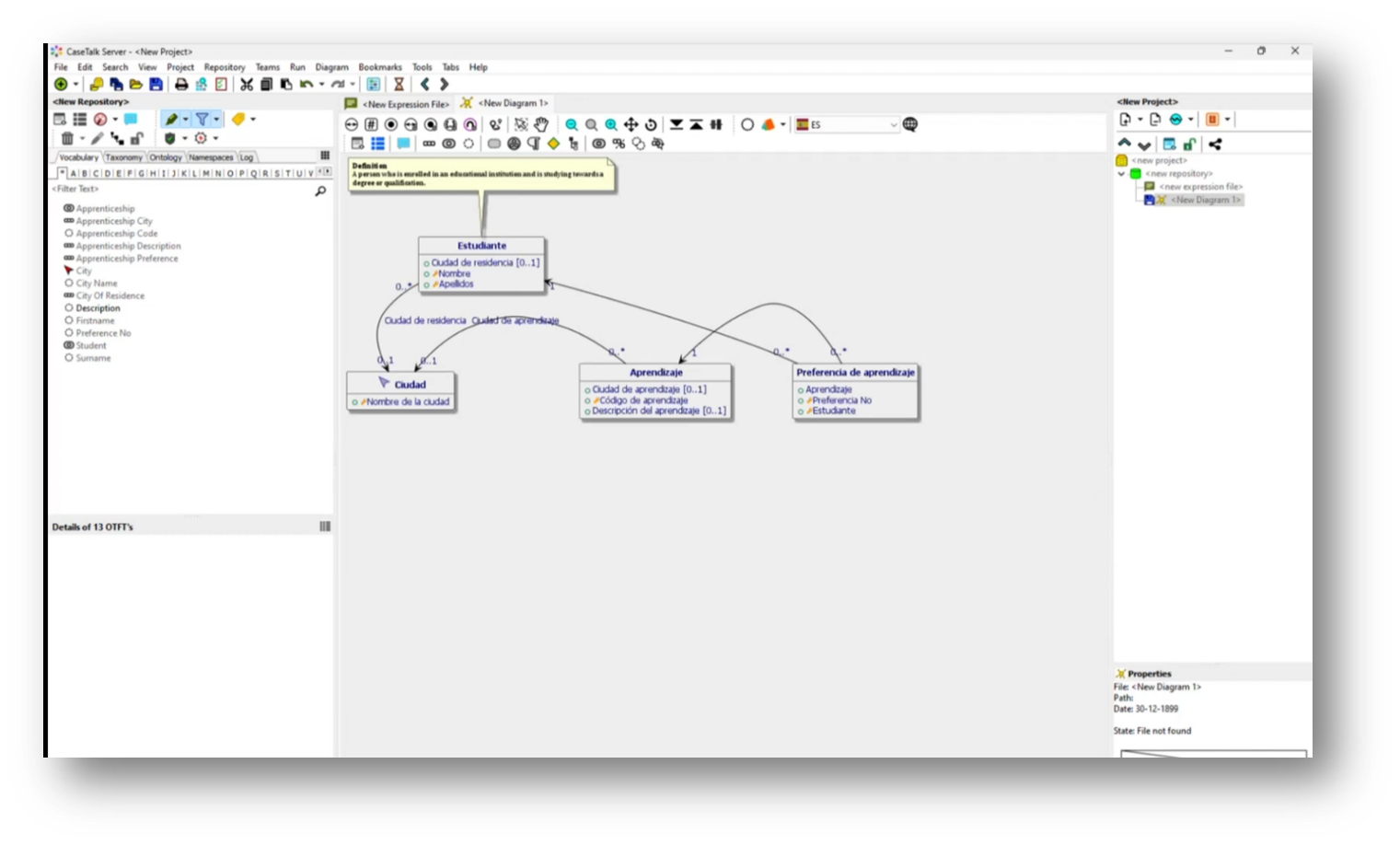
Figure 41 Data Model Translated into Spanish
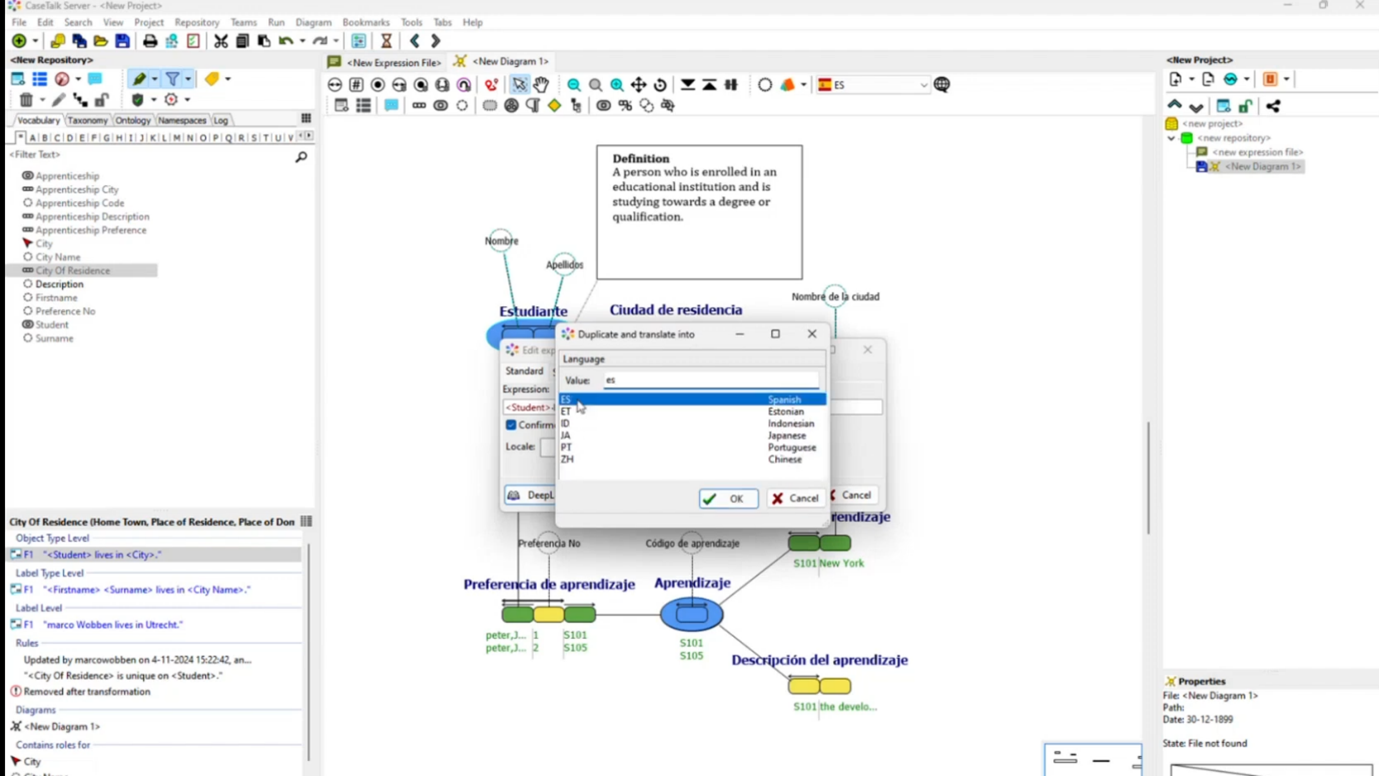
Figure 42 Translating the Expression into Spanish
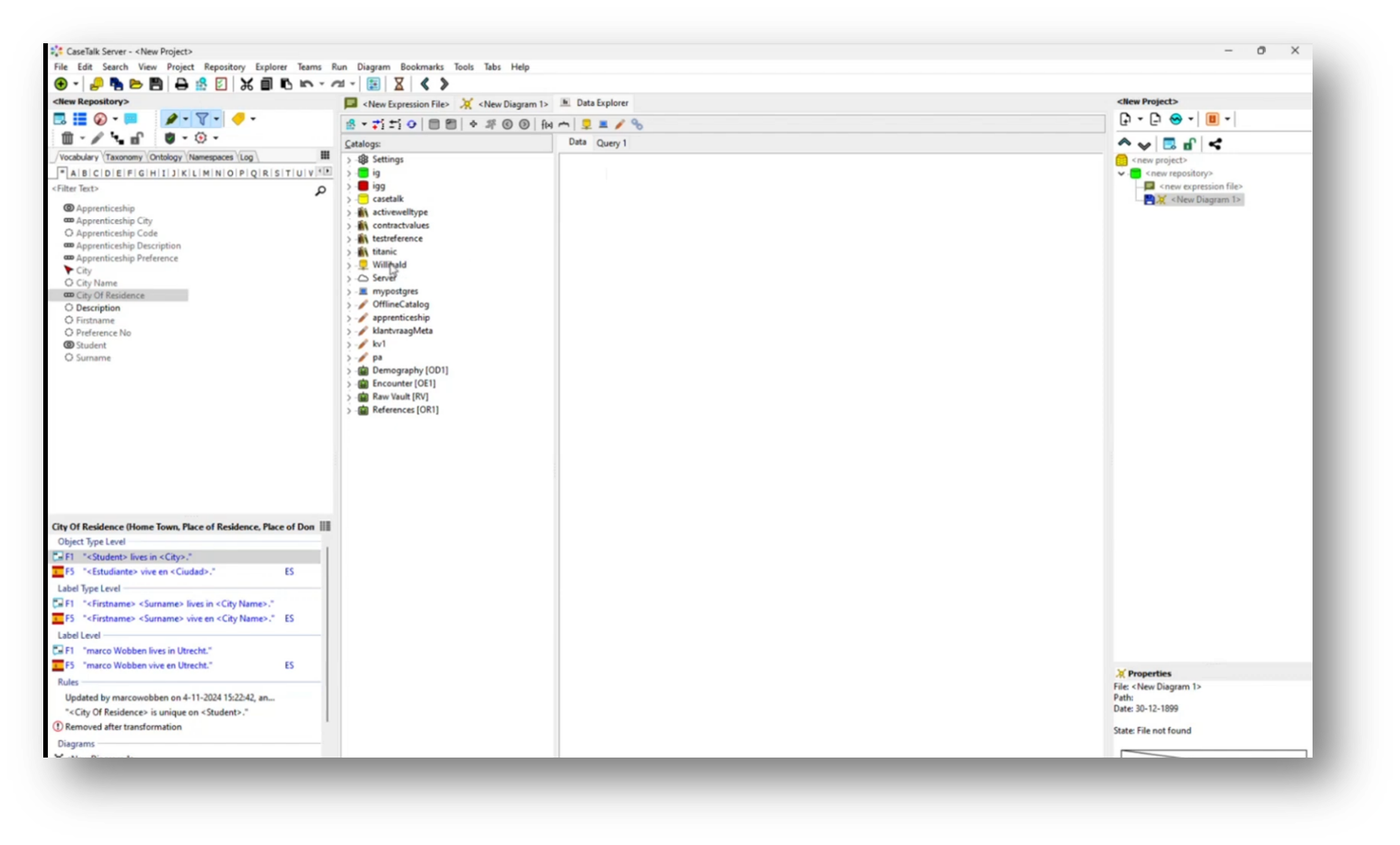
Figure 43 Data Explorer
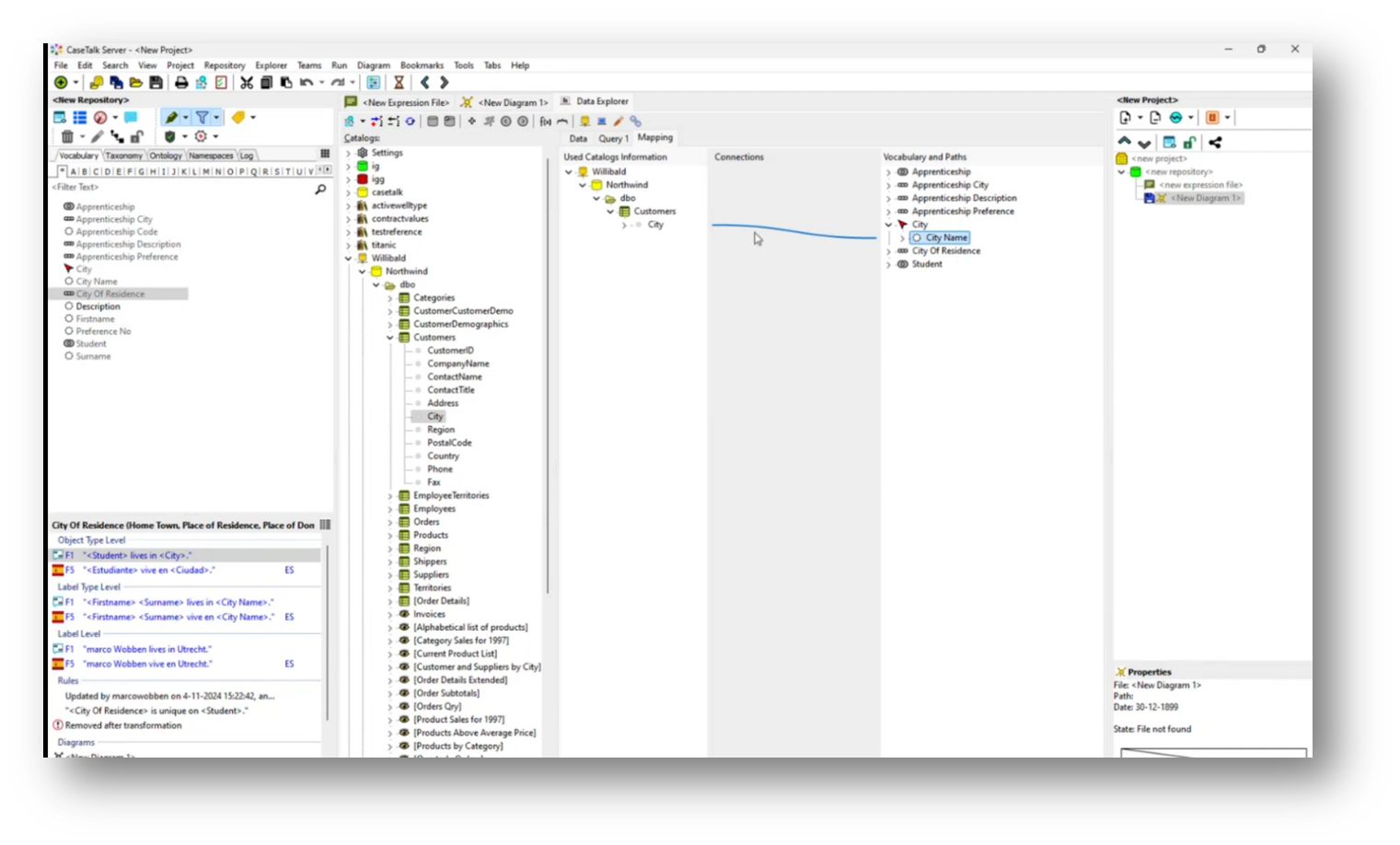
Figure 44 Vocabulary and Paths
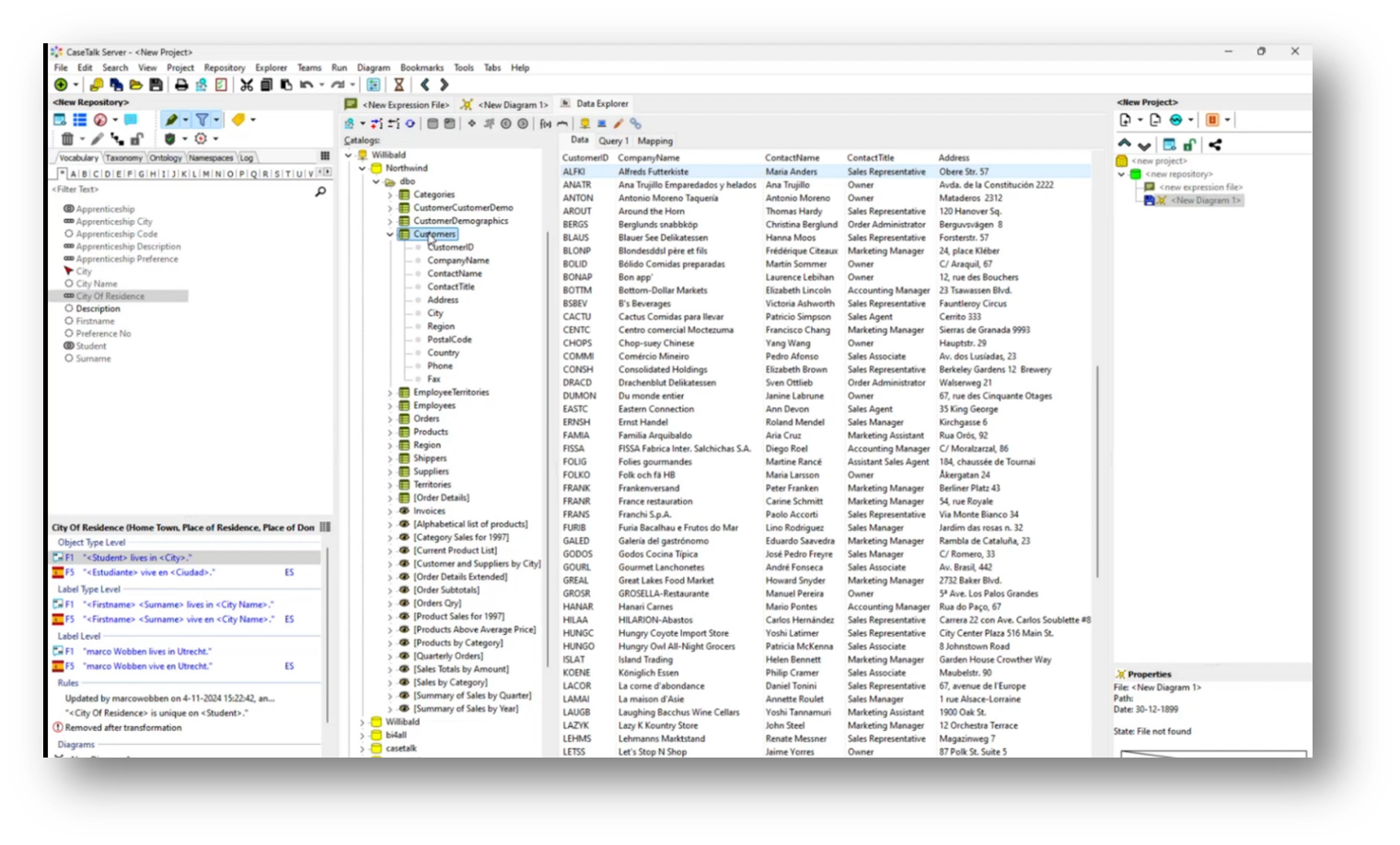
Figure 45 Accessing Customer Database via Data Explorer
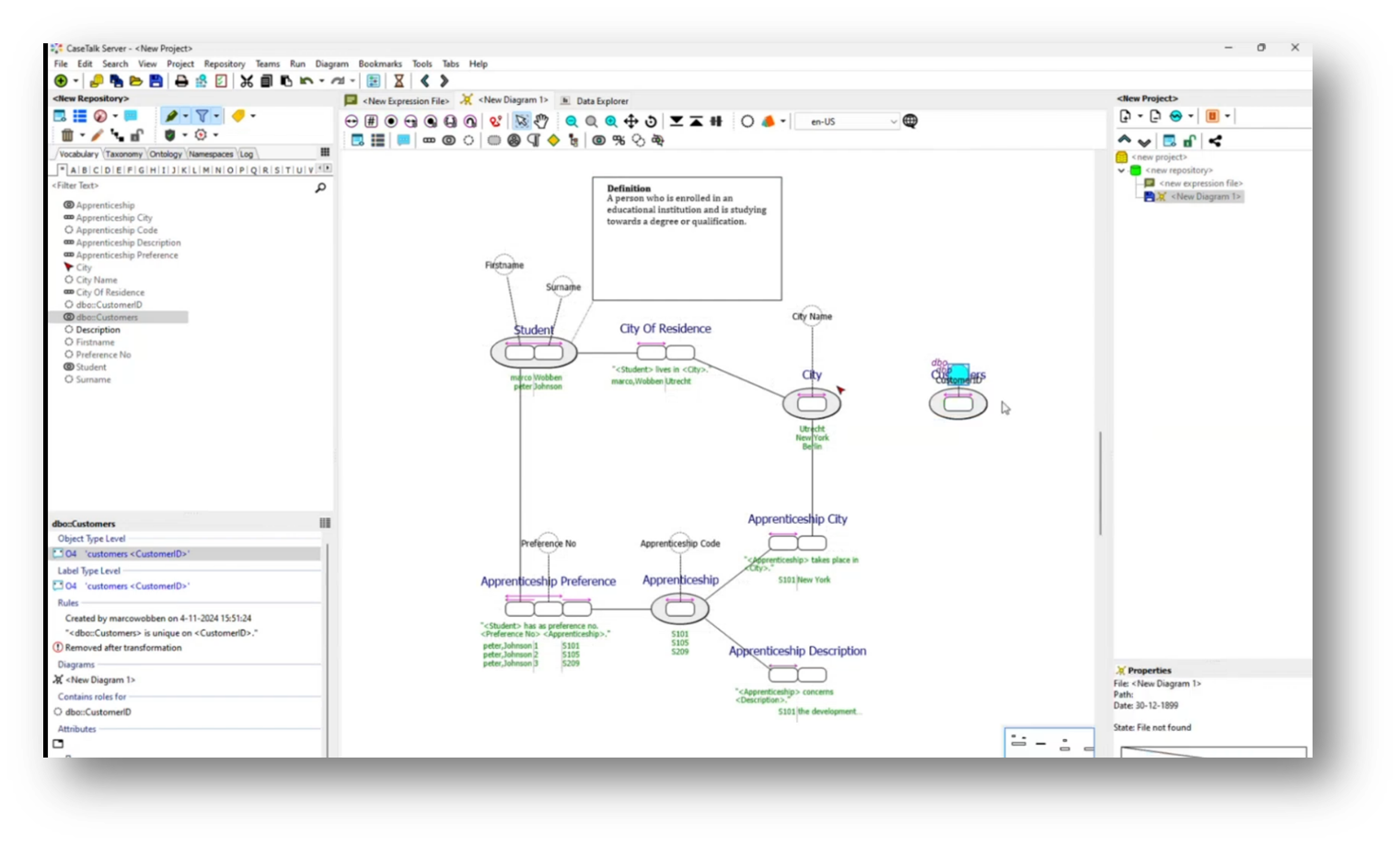
Figure 46 Updated Data Model
Temporal Data Tracking and Communication in Data Management
A discussion starts on the importance of tracking temporal information in urban environments, particularly how to manage timelines related to city living and individual movements. Using transaction time as an example, it emphasizes the need for clarity in communication with stakeholders by isolating relevant timelines—whether they pertain to past, present, or future information.
Marco highlights a real-world application involving a Dutch company leveraging a product for an SAP migration, which manages a vast database of uniquely named, tracked, and versioned terms to enhance business value beyond mere data migration. The product also integrates with various modelling tools and supports governmental services, showcasing its versatility through API integrations and collaboration with established data management techniques like Data Vault Builder.
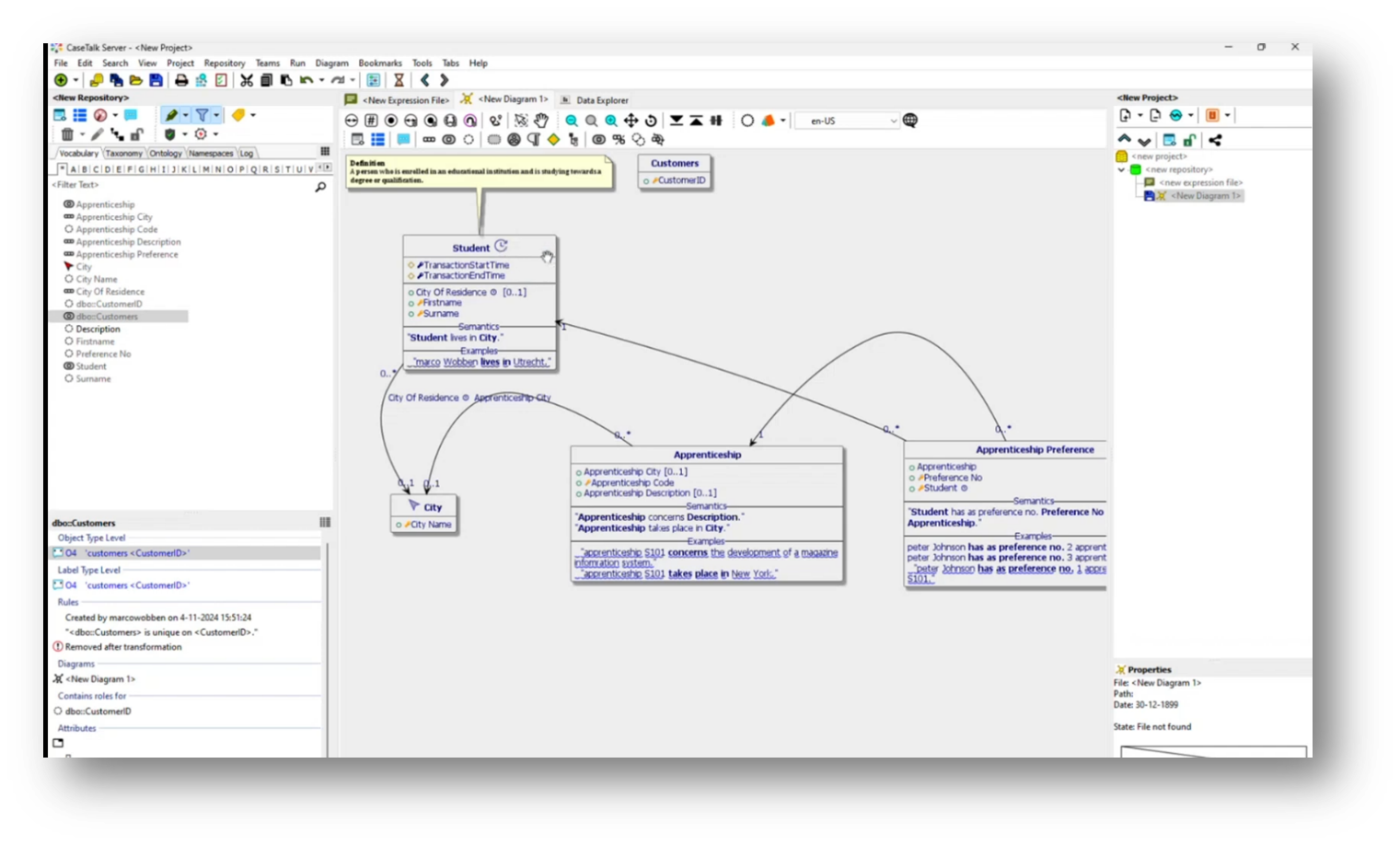
Figure 47 Updated Relational Model
Figure 48 Information Web

Figure 49 Information Architecture

Figure 50 CaseTalk Supports
Understanding and Meeting Data Requirements
Marco emphasizes the importance of effectively translating business requirements into data requirements, highlighting the necessity of engaging with business stakeholders through informal discussions to extract critical concepts. While technical cataloguing products can document the live environment, the speaker advocated starting with free-format interviews to gather nouns and verbs, which can serve as a foundation for understanding business communication. However, to truly comprehend business objectives, it's crucial to verify the extracted concepts through fact expressions, as demonstrated through initial diagramming that resonates with stakeholders. Ultimately, the key takeaway is that facilitating open dialogue helps in identifying the essential data requirements needed for stakeholders to fulfil their roles effectively.

Figure 51 'Just the Facts' Promotion
Business Strategy and Data Management
By clearly defining value propositions, capabilities, and relevant information concepts, you can align business architecture with strategy. Marco goes on to emphasise the need for upper management to articulate their ideas through factual statements that connect to meaningful nouns, fostering better communication between business and IT. This ongoing dialogue is crucial for linking requirements to existing systems and data. Marco also notes the effectiveness of using live demonstrations to illustrate these concepts, as seen in the speaker's book, enhancing understanding and practical application.
An attendee raises a question on customizing metadata for information elements, allowing users to include reference data, stakeholder information, and approval details when generating database scripts. This process not only creates normalized database tables but also adds a layer of views, enabling users to see their own terminology replaced with the relevant data from the records in the tables.
Data Modelling and Business Language in Technology
The webinar closed with Marco highlighting the comprehensive process of the Demo. From initiating the interview to utilizing artifacts within applications and databases, he emphasised the importance of databases alongside tools such as Python, APIs, and XML. A free evaluation edition of relevant tools was mentioned, allowing users to explore described cases despite limitations in functions and size.
If you want to receive the recording, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!