
Data Storage & Operations for Data Executives

Executive Summary
This webinar provides an overview of data storage architecture and consistency, challenges and solutions for data management in a data lake house, edge computing and data architecture, semantic unification, data fabric, and the role of data fabric in achieving semantic consistency and data unification. Howard Diesel discusses data orchestration and database organisation, the challenges of data unification and justifying costs, the importance of getting things right in decision-making, decision quality and data management strategy, decision-making and analysis in data management and business, challenges in decision-making, the decision-making process and framework, data trust, better decision making and the decision-making loop, the CYNEFIN approach to decision making, and decision support systems and modelling.
Webinar Details:
Title: Data Storage & Operations for Data Executives
Date: 02 February 2022
Presenter: Howard Diesel
Meetup Group: Data Executives
Write-up Author: Howard Diesel
Contents
Executive Summary
Webinar Details
Data Storage and Operations Essential Concepts
Overview of Data Architecture and Consistency
Challenges and Solutions for Data Management in a Data Lake House
Edge Computing and Data Architecture
Semantic Unification and Data Fabric
The Role of Data Fabric in Achieving Semantic Consistency and Data Unification
Data Orchestration and Database Organization
The Challenges of Data Unification and Justifying Costs
The Importance of Getting Things Right in Decision-making
Decision Quality and Data Management Strategy
Decision-Making and Analysis in Data Management
Decision-Making and Analytics in Business
Challenges in Decision-making
Decision-Making Process and Framework
Data Trust and Decision-Making
Better Decision-making and the Decision-Making Loop
The CYNEFIN Approach to Decision-making
Decision Support Systems and Modelling
Data Storage and Operations Essential Concepts
The topic of data Storage and Operations is introduced and Howard Diesel reviews essential concepts. He mentions a large body of documents that may need reviewing and briefly going over different concepts. Howard emphasises that the focus is on data processing, not transactions, and discusses the implications of choosing between ACID (consistency) and BASE (availability). He notes that ACID requires a scheme in place. At the same time, BASE does not, and the importance of understanding data processing, data architecture, and operations from a DMBOK fundamentals perspective is highlighted. Different data architecture types, including centralised ones, are also mentioned.

Figure 1 Essential Concepts

Figure 2 Database Processing Types: ACID vs BASE

Figure 3 Implications ACID vs BASE
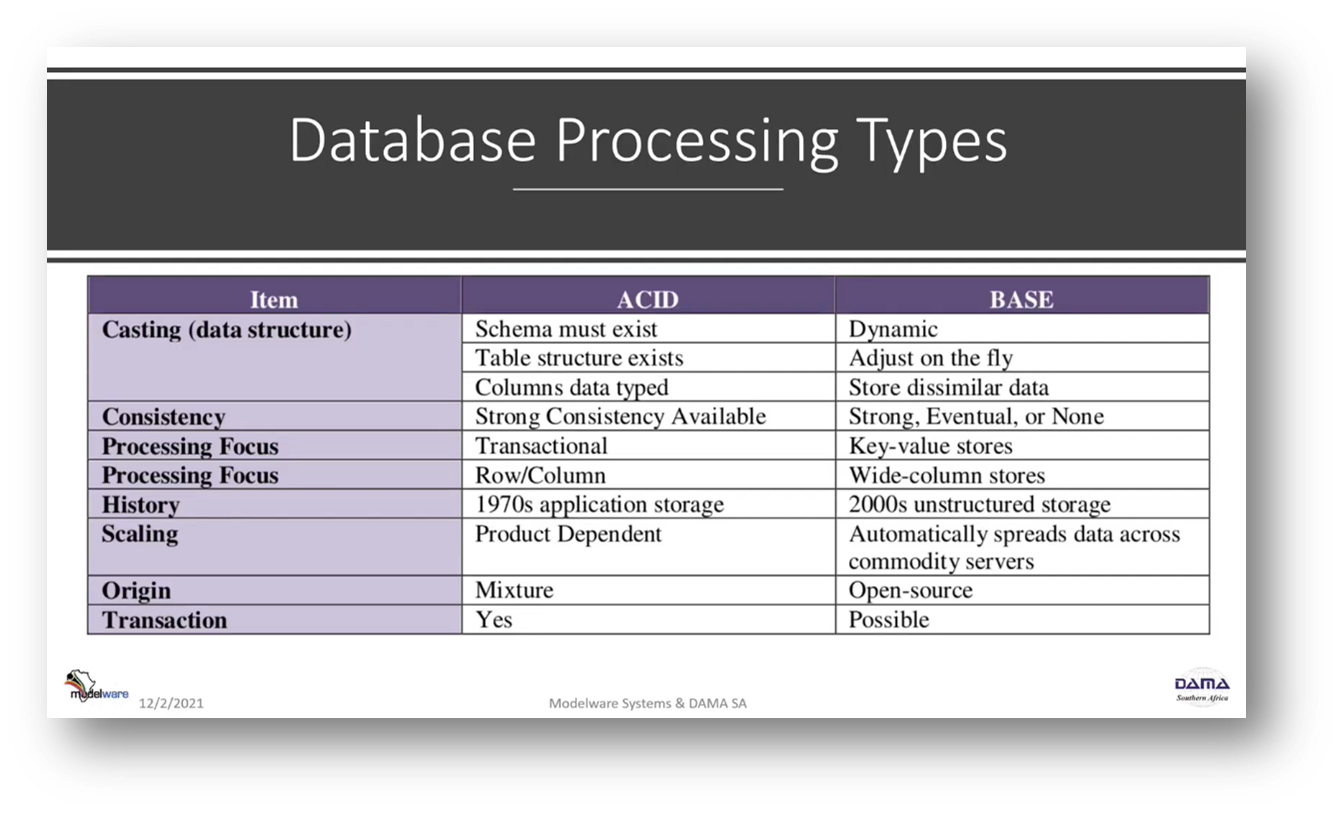
Figure 4 Database Processing Types
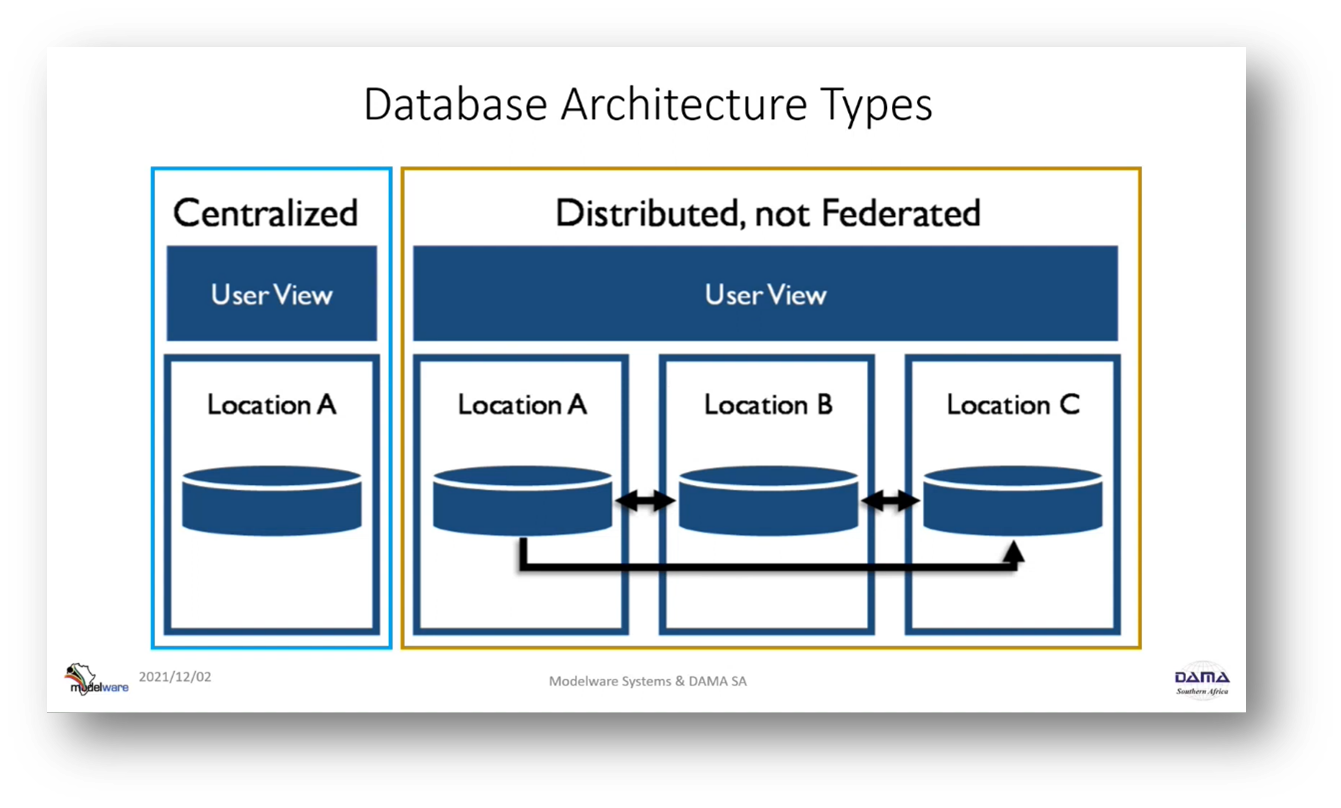
Figure 5 Database Architecture Types
Overview of Data Architecture and Consistency
Howard emphasises the importance of maintaining consistent data across distributed locations to ensure data quality and overcome centralised failure. Different approaches, such as replication and mirroring, are used to keep data up to date in various locations. Still, as the data architecture becomes more distributed or federated, the consistency of data elements across copies becomes more challenging. Consistency is related to the data quality dimension and involves checking if data elements have moved correctly between the system of record, master data, data warehouse, and business intelligence. Howard introduces a scenario where the old data warehouse is transformed into a data lake house with a shared catalogue on top, and a consumption layer is established above the data lake house for data usage. Examples of federated databases and blockchains are referenced, and the CAP theorem is mentioned, highlighting the trade-offs between consistency, availability, and tolerance for system failures.
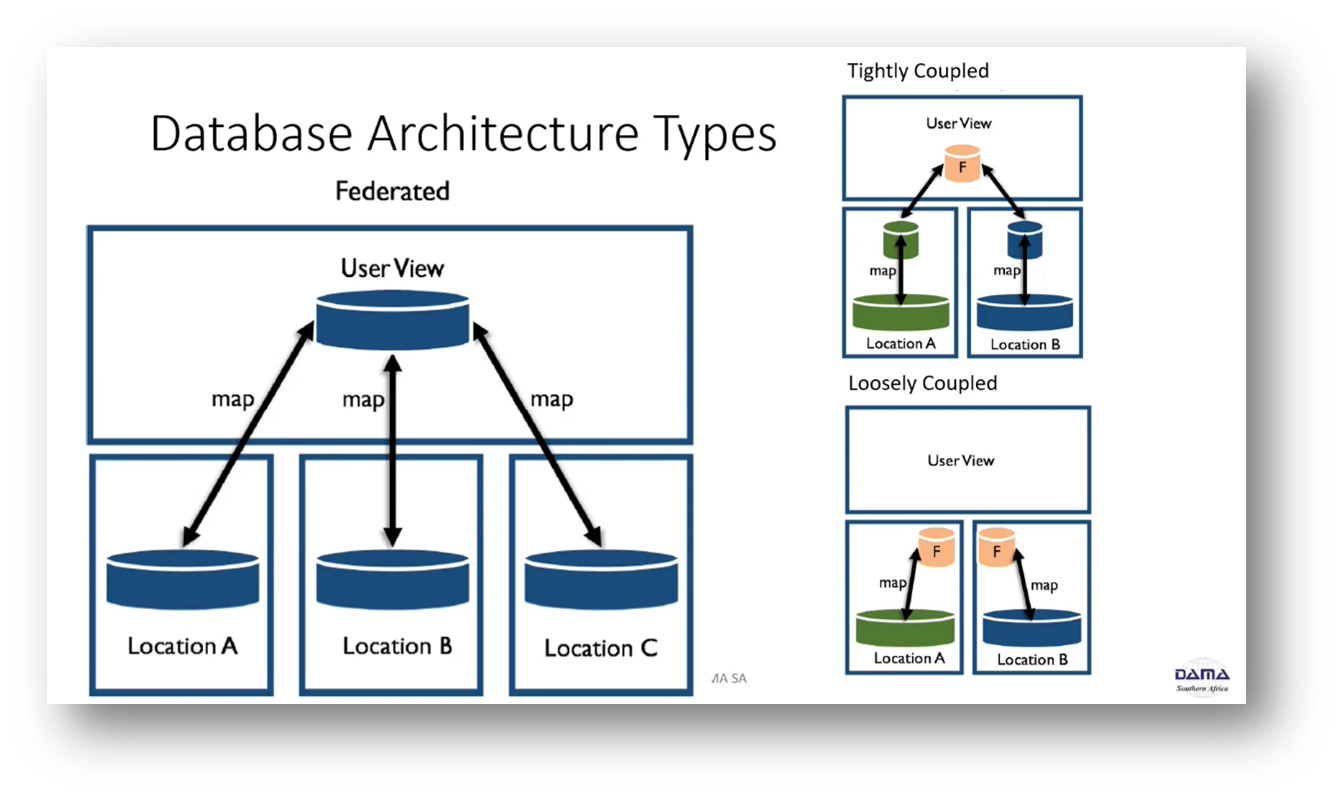
Figure 6 Database Architecture Types Continued

Figure 7 Distributed Systems: CAP Theorem
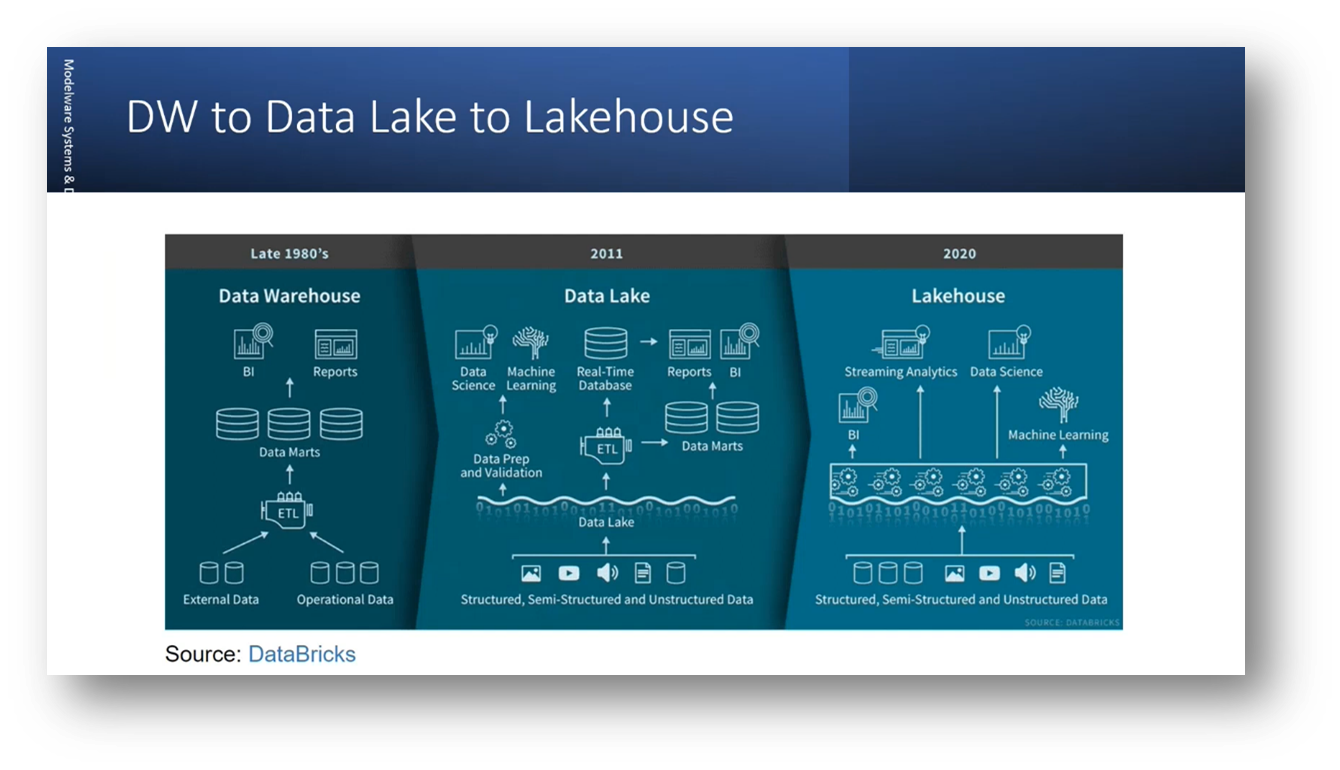
Figure 8 DW to Data Lake to Lakehouse
Challenges and Solutions for Data Management in a Data Lake House
The data lake faces data mutation, quality control, and data cleaning challenges. The data lake house concept was developed to reduce the need for external processing and preparation by consolidating all functions into a single area. It contains structured, semi-structured, and unstructured data; batch and streaming layers ingest data. The bronze, silver, and gold model refers to data quality and storage levels within the data lake house. Progressing through the bronze, silver, and gold layers indicates an increasing value and improvement in data quality. The need for edge computing and associated advancements in data management drove the introduction of the data mesh.
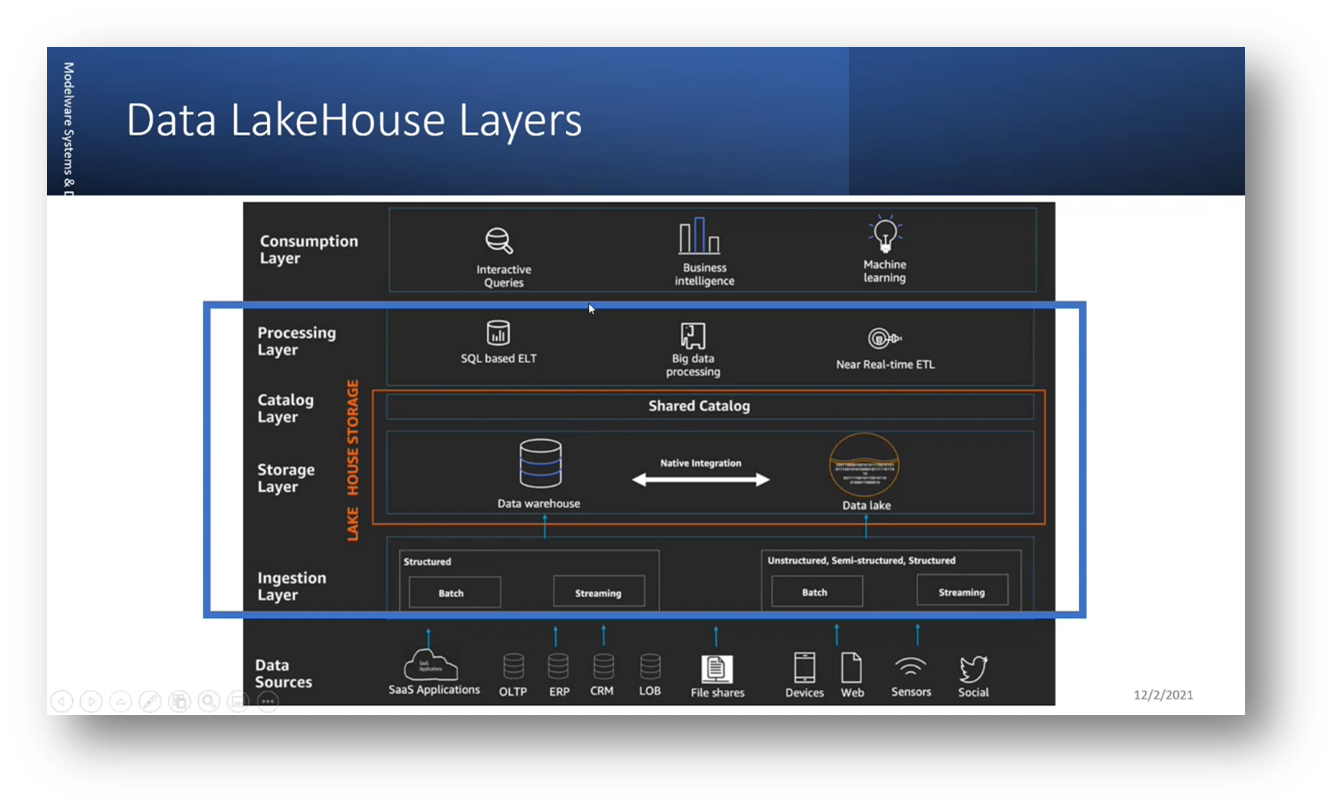
Figure 9 Data LakeHouse Layers

Figure 10 Additional Features to Data Lake
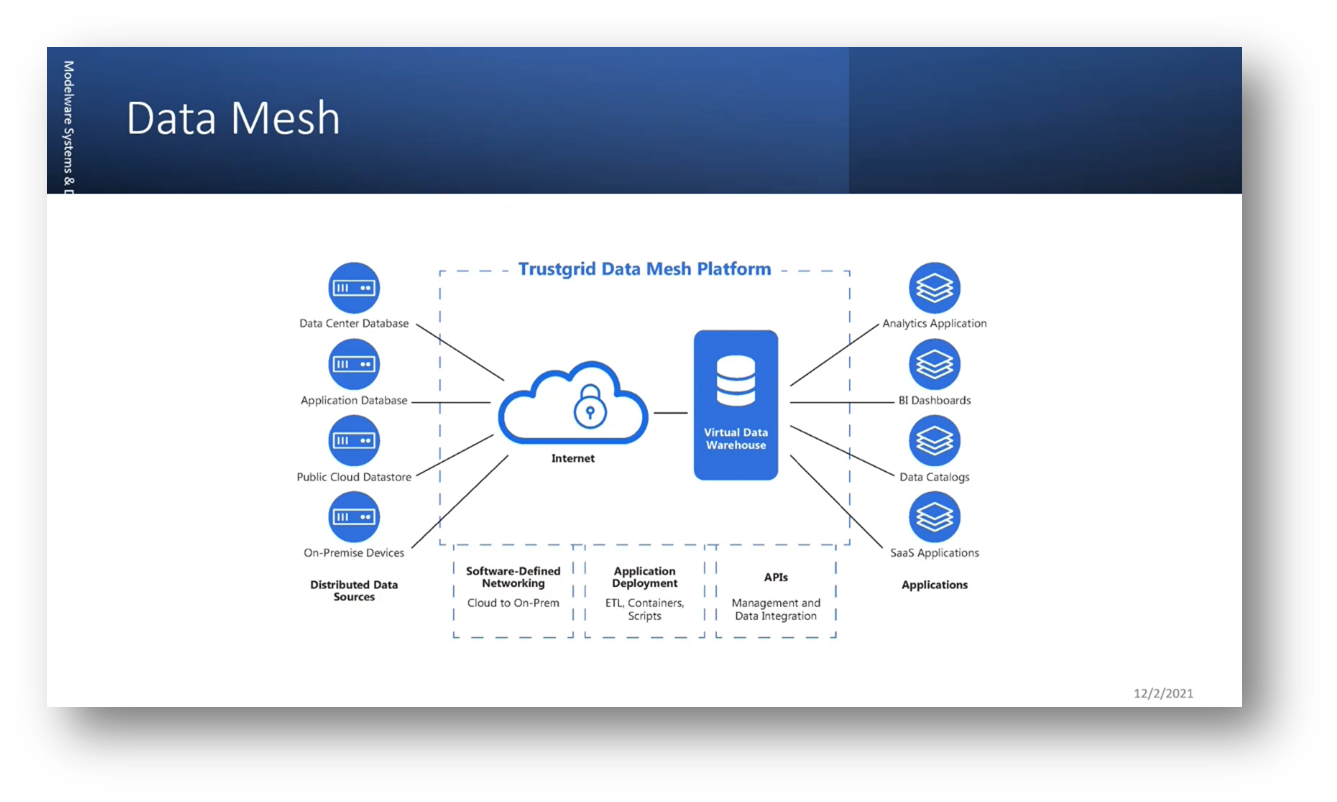
Figure 11 Data Mesh

Figure 12 Harmonized Mesh (Azure)

Figure 13 Data Mesh Conclusion
Edge Computing and Data Architecture
Edge computing is crucial for cases that require high bandwidth and throughput, such as trading platforms. Decentralising clouds and having nodes closer to users is key to efficient edge computing. A mesh provides governance, catalogues, and monitoring in different regions, while data products enable analytics at a subject or product area, allowing interaction between different data products.

Figure 14 Edge Computing
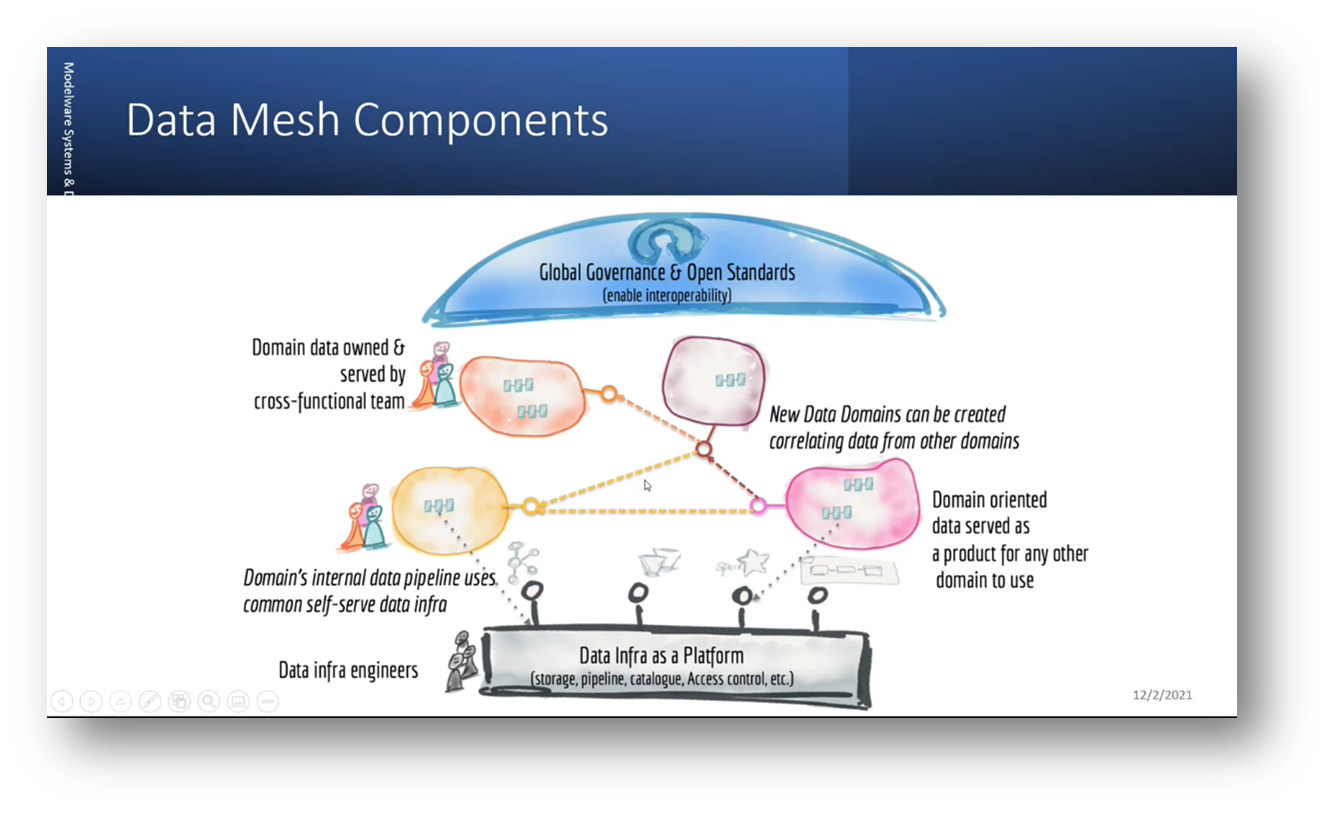
Figure 15 Data Mesh Components

Figure 16 Data Fabric - Key Pillars of a Comprehensive Data Fabric
Semantic Unification and Data Fabric
The shift towards decentralisation in cloud computing, which breaks down public clouds into multiple private clouds for more flexibility while maintaining the same infrastructure and platform, is being discussed. The focus is on democratisation at scale, enabling data products to communicate with each other and shifting the focus to a data product level. Data is a product for any domain, focusing on machine learning within a certain area. The concept of a "data fabric" is introduced as an approach to handling semantic unification challenges, which arise due to semantic challenges in the data lake where data sets from different sources may have different meanings for the same columns. The need for semantic unification arises to ensure consistency and compatibility across data sets.
The Role of Data Fabric in Achieving Semantic Consistency and Data Unification
The data fabric concept addresses the issue of incorrect connections and correlations in data analysis by seeking semantic unification across different data sets to establish a consistent meaning. Active metadata is created to ensure semantic consistency, and the knowledge graph is introduced as the next step in the data-centric approach. A data-centric architecture with a common meaning is presented as the desired outcome of the data fabric system. The data lake requires semantic consistency to discuss data at the same grain, and Pool Party exemplifies the capability of active metadata to generate data products. Ensuring a common view of data with diverse meanings and scaling can be achieved through machine learning and AI unification or by building knowledge graphs. The architecture described emphasises an automated approach.
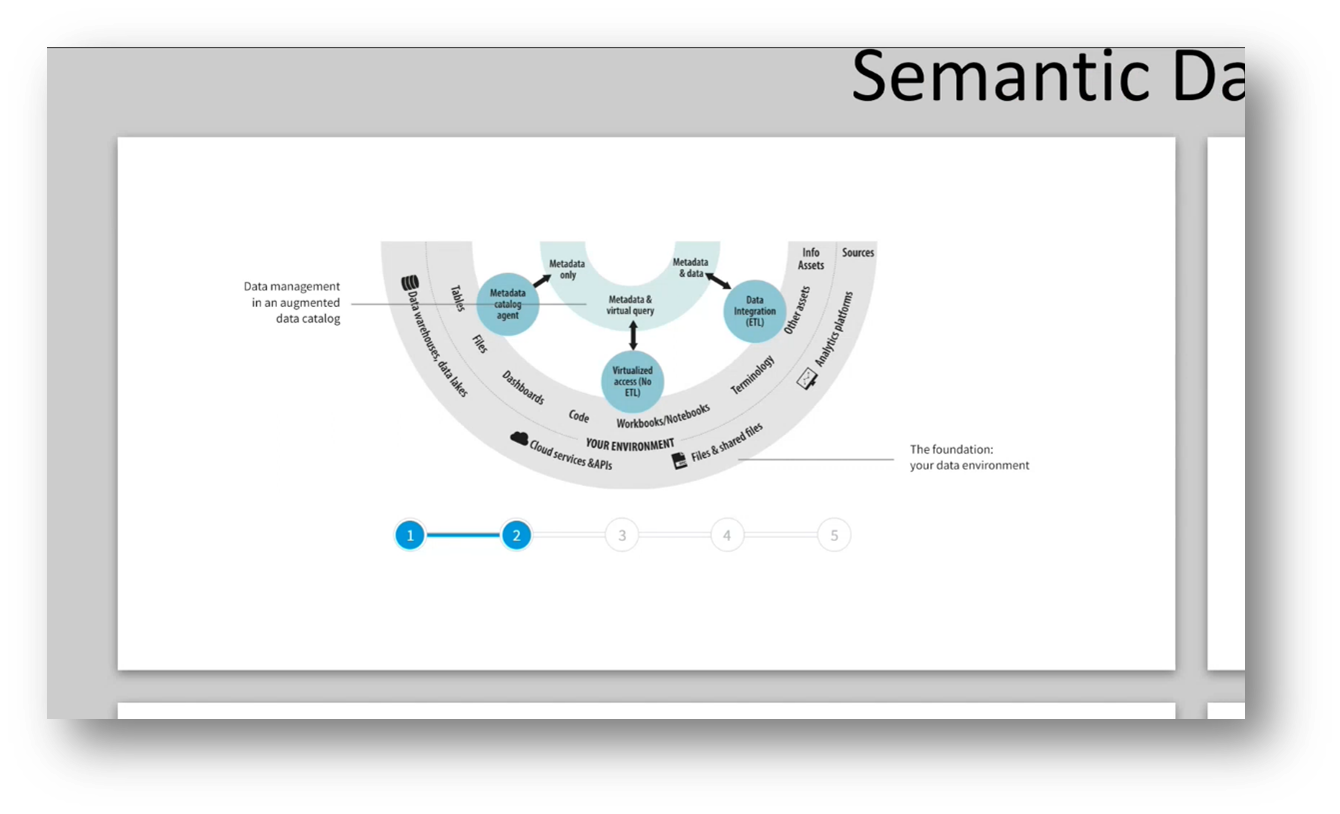
Figure 17 Semantic Data Fabric Part 1
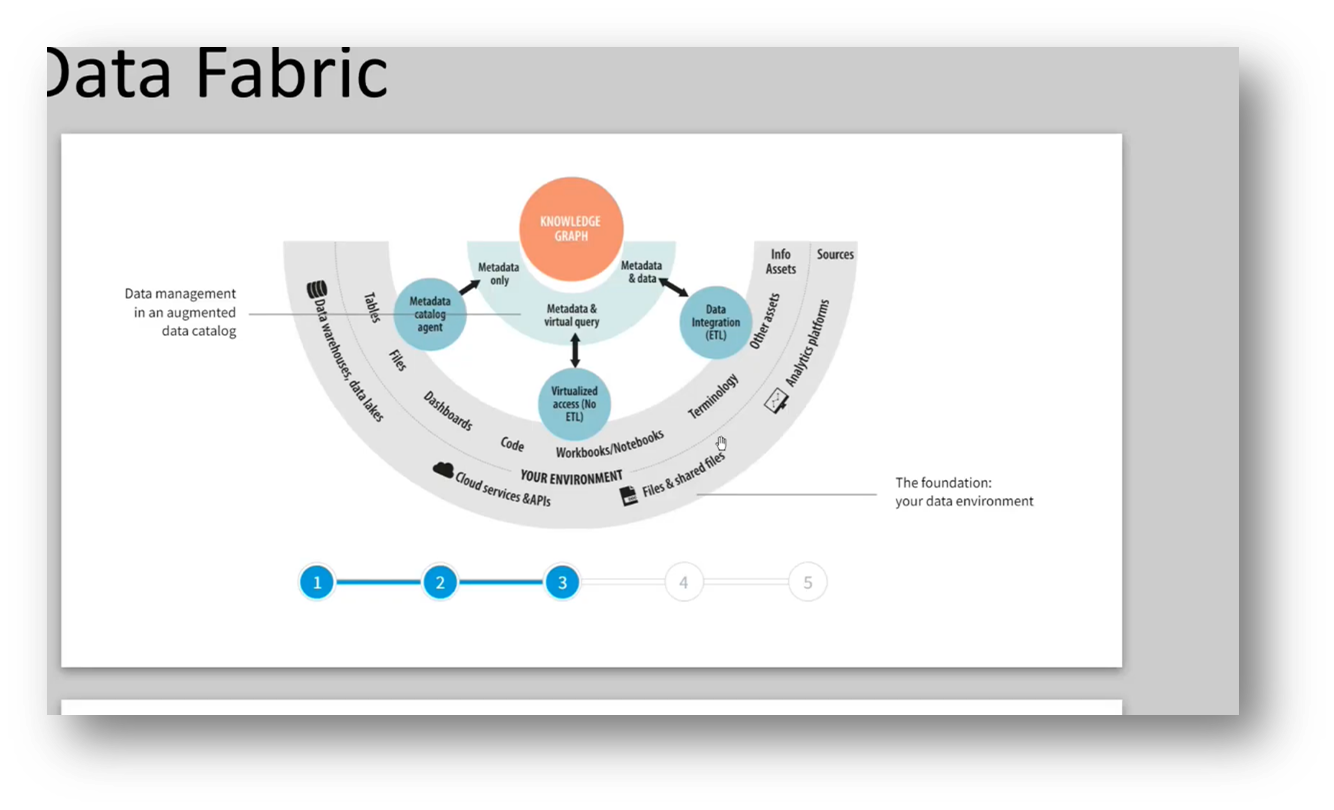
Figure 18 Semantic Data Fabric Part 2

Figure 19 Semantic Data Fabric Part 3
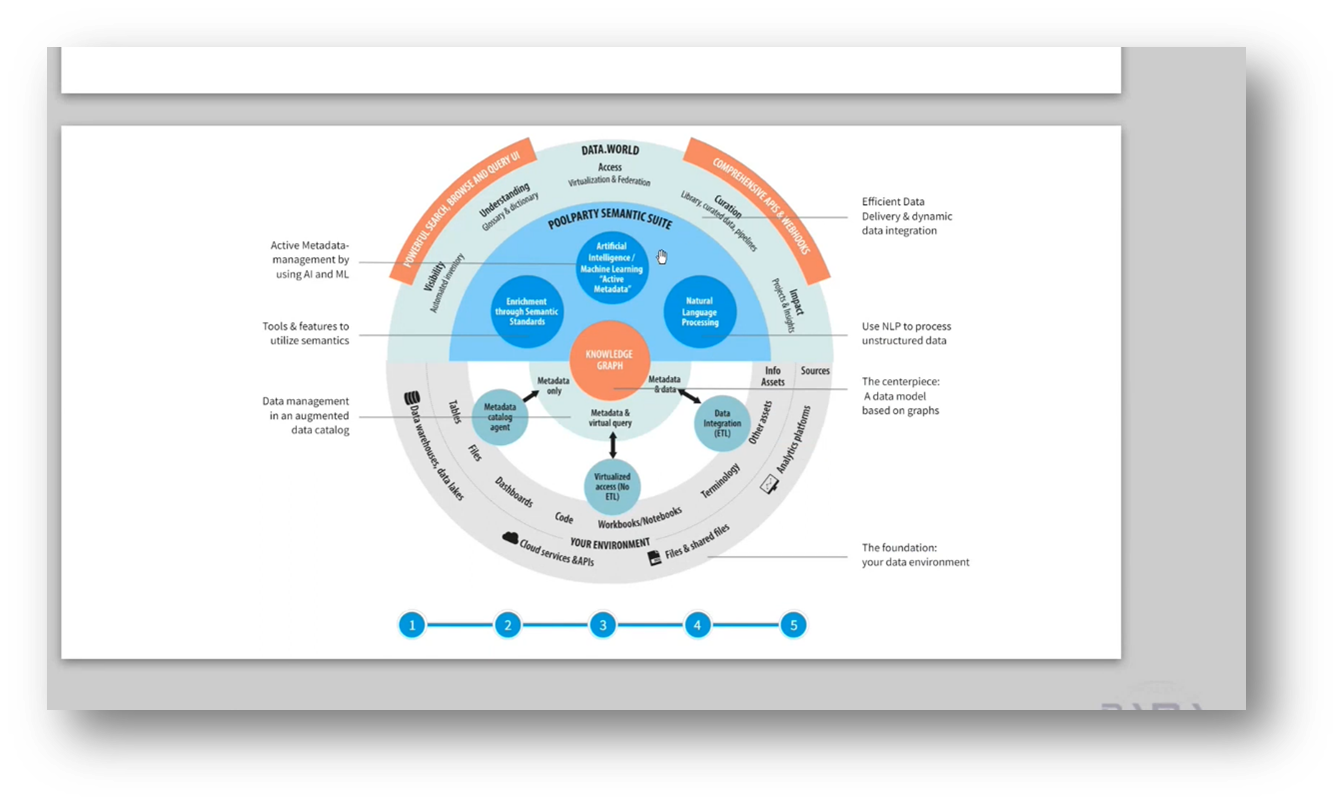
Figure 20 Semantic Data Fabric Part 4
Data Orchestration and Database Organization
Automated data orchestration and dynamic data integration are made possible through AI algorithms, which can simplify and automate data integration over a connected knowledge graph. Semantic unification analytics is performed over a knowledge graph with metadata to achieve a canonical model. Gartner and Pool Party have claimed the ability to build knowledge graphs using AI and machine learning. There are different approaches to data unification, such as data fabric. Microsoft continues to publish industry data models as part of the common data model. Data storage is categorised into non-hierarchical relational and non-relational databases, and the ability to dynamically piece together data products is an interesting development in this space.
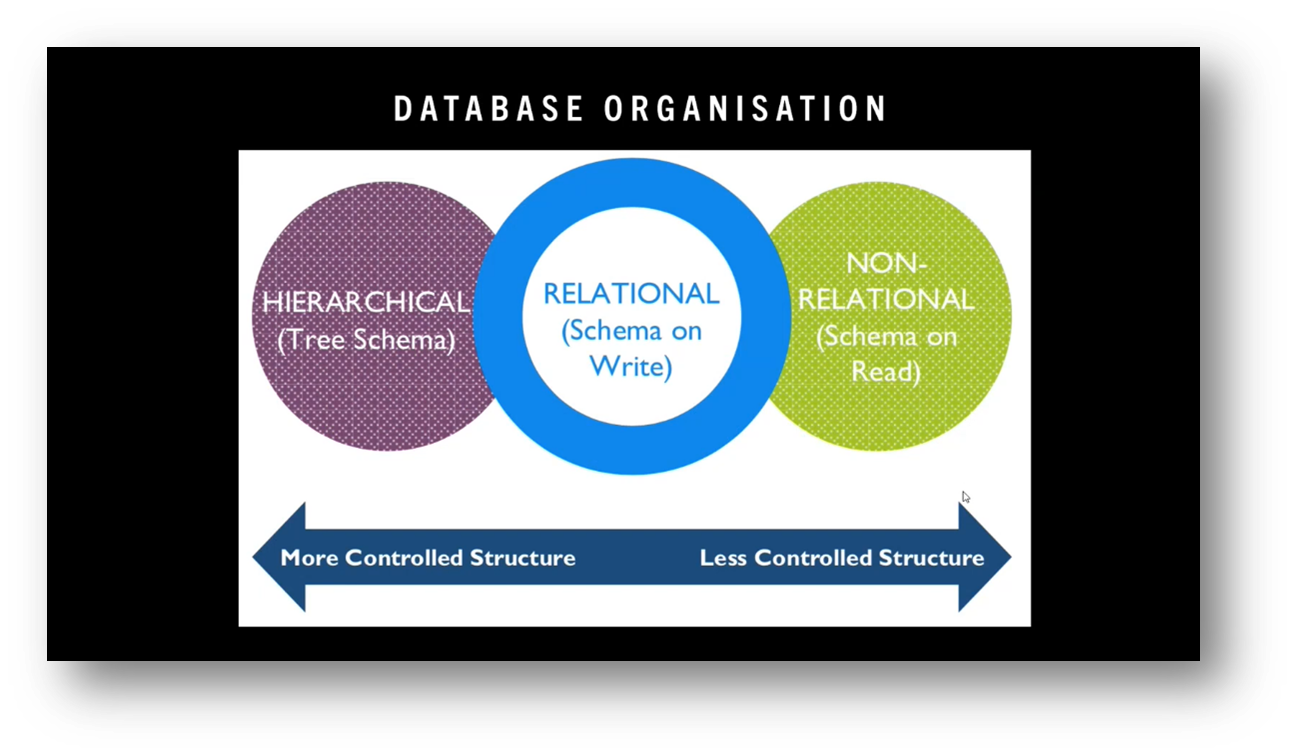
Figure 21 Database Organisation

Figure 22 Semantic Unification (Canonical)
The Challenges of Data Unification and Justifying Costs
The common data model poses semantic unification challenges due to different data sources and semantics. Ignoring these challenges may lead to lost value and chaos. Two approaches to address unification are data fabric and data mesh, where data mesh relies on domain-focused efforts, while data fabric utilises technology. The unification process involves a pipeline that pulls all the data together. The executive's role is to justify the costs of data storage platforms, such as Synapse. Data governance focuses on doing the right things, while data storage executives focus on doing things right. Platforms like DataBricks and Azure Data Factory can be expensive, requiring careful cost management to address concerns about potential cost increases over time and manage expenses.

Figure 23 Semantic Differences Challenge

Figure 24 Unification Approach
The Importance of Getting Things Right in Decision-making
The success of a project depends on the justification of decisions and actions taken by the executive. To achieve this, it is essential to ensure that the correct data is provided to the appropriate personnel at the correct time. However, latency and integration problems in storage areas should not be overlooked. The correct semantics, improved analysis, and pricing are required to achieve unification. According to the Harvard document, the right simplification is portrayed as a right triangle. This triangle consists of the right people, the right data, and the right analysis, leading to the right decisions. Several factors must be considered to make effective decisions, including business analysis, cause and effect analysis, analytics, decision-making techniques, and data quality expectations. Finally, it is essential to continuously obtain the right data to keep the project on track.

Figure 25 Data Storage & Operations for Data Executives

Figure 26 Doing Things RIGHT

Figure 27 The Right Simplification
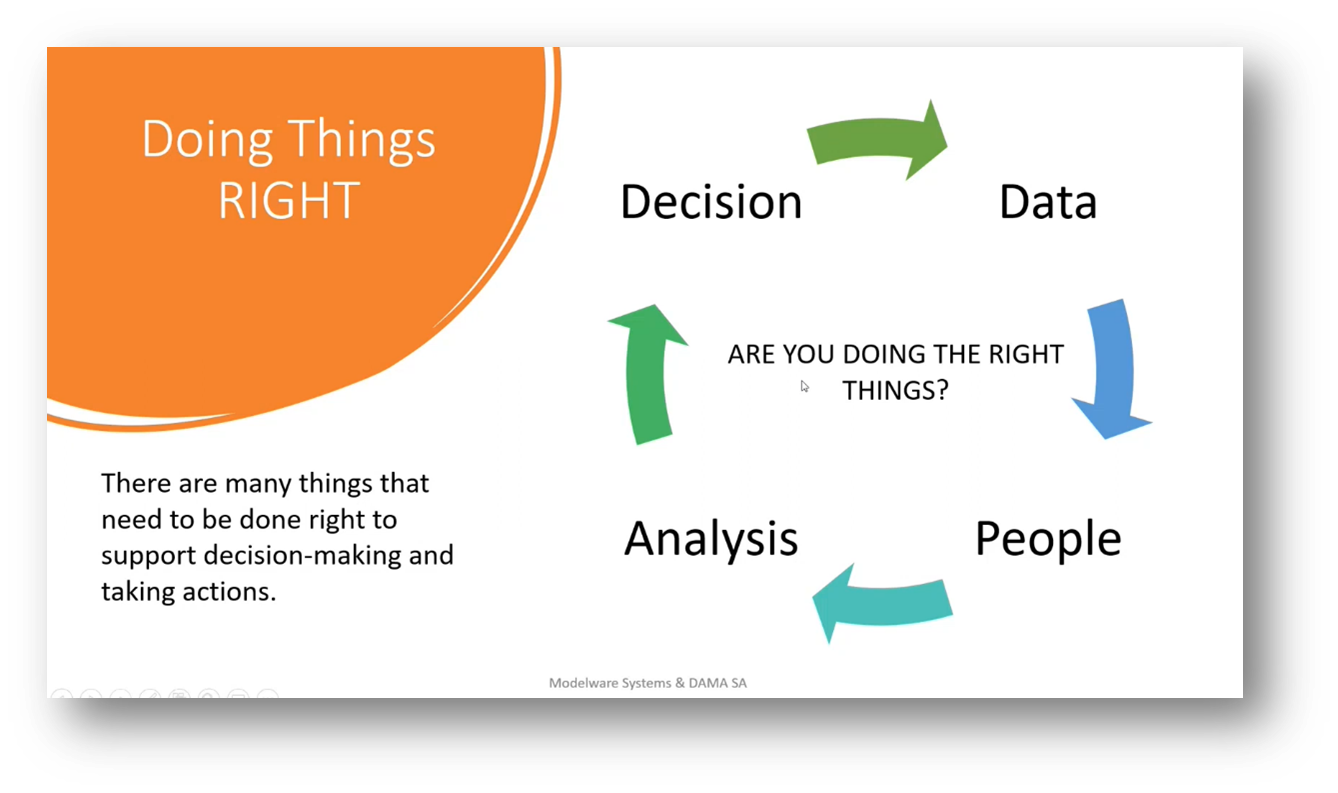
Figure 28 Doing Things RIGHT: Data, People, Analysis, Decision

Figure 29 RIGHT Data (Fit-For-Purpose)
Decision Quality and Data Management Strategy
The Sedaya and the NDMO data management strategy involves conducting privacy and ethics impact assessments before making any moves. The timing perspective is important to consider, as decisions made now may need to be reevaluated in the future. The goal is to achieve the right analysis with the right people at the right time, leading to the right decisions. Business decision quality is prioritised over data quality, with constant analysis of decision types and the required combination of people, processes, and data. Metadata plays a crucial role in decision-making by ensuring the right semantics and context are present in the data. Choosing a suitable database management structure involves focusing on data types and considering the use case.

Figure 30 How to Choose the DBMS for your Data. 1. Data Type
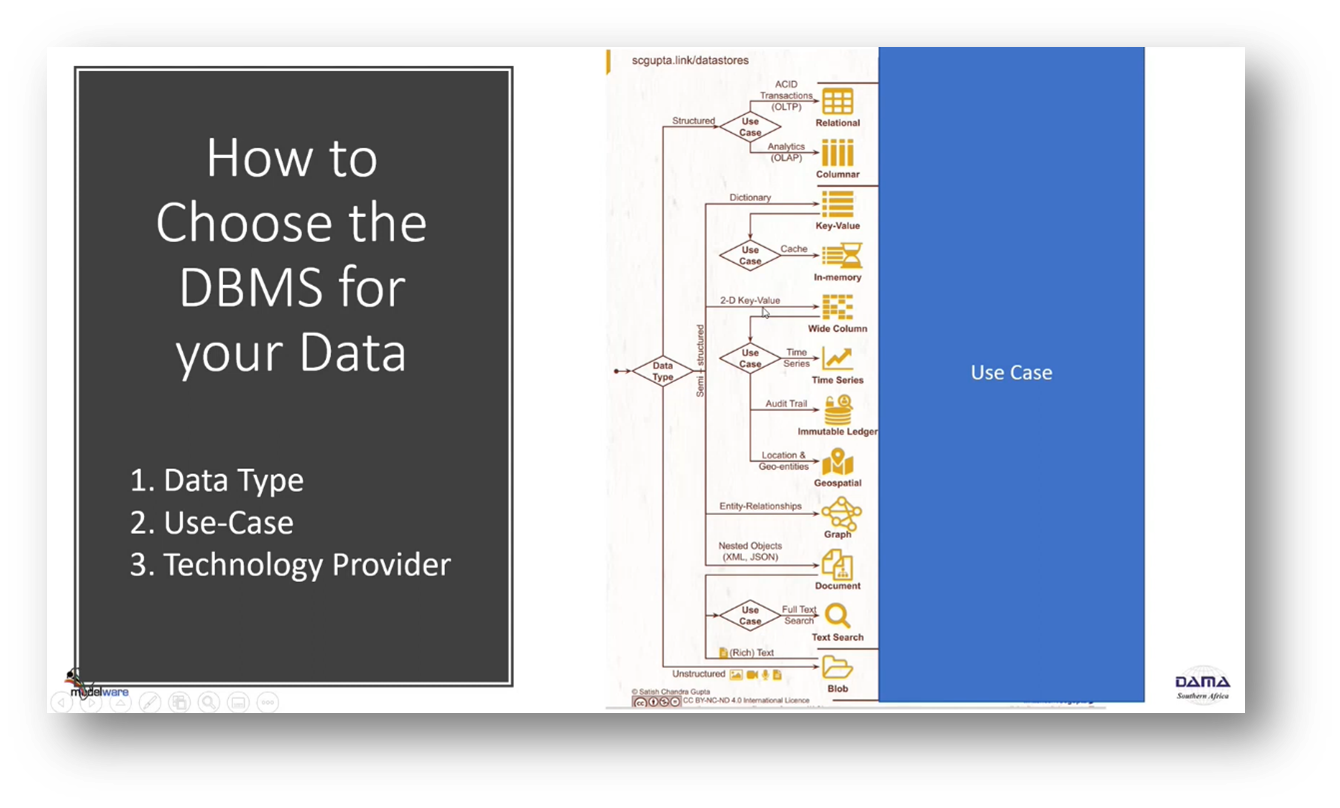
Figure 31 How to Choose the DBMS for your Data. 2. Use Case

Figure 32 How to Choose the DBMS for your Data. 3. Technology Provider
Decision-Making and Analysis in Data Management
To make informed decisions in cloud technology, it is crucial to understand the specific use case and consider the options available in AWS, Azure, Amazon, or a cloud-agnostic platform. Additionally, organisations must have a suitable culture, structure, and roles to execute decisions effectively. The focus should be building decision-making teams and using different team structures for decisions. Analysis is also essential and can be categorized into known knowns, known unknowns, and unknown unknowns, depending on the level of certainty. Overall, a thorough understanding of the cause-and-effect relationship is key to making effective decisions in the cloud technology space.

Figure 33 Right PEOPLE

Figure 34 Right PEOPLE and CULTURE

Figure 35 Right ANALYSIS
Decision-Making and Analytics in Business
Howard summarises the importance of utilising different types of analytics in decision-making processes. Descriptive analytics provides information on what happened, while diagnostic analytics determines why certain events occurred. Predictive and prescriptive analytics use AI and big data to predict future outcomes and suggest actions to improve results, whereas cognitive analytics aims to understand cause-and-effect relationships and identify areas of improvement. The OODA (Observe, Orient, Decide, Act) loop is a decision-making technique, and digital decision-making is suitable for decisions with clearly understood cause-and-effect relationships. Confirmatory analytics is used in a complicated environment where promising practices are followed, while exploratory analytics is used in a complex environment where hypothesis testing is necessary. Action and experimenting are recommended when facing chaos and a lack of data. Different decision-making approaches suit different scenarios, with experts playing a crucial role in complicated environments.
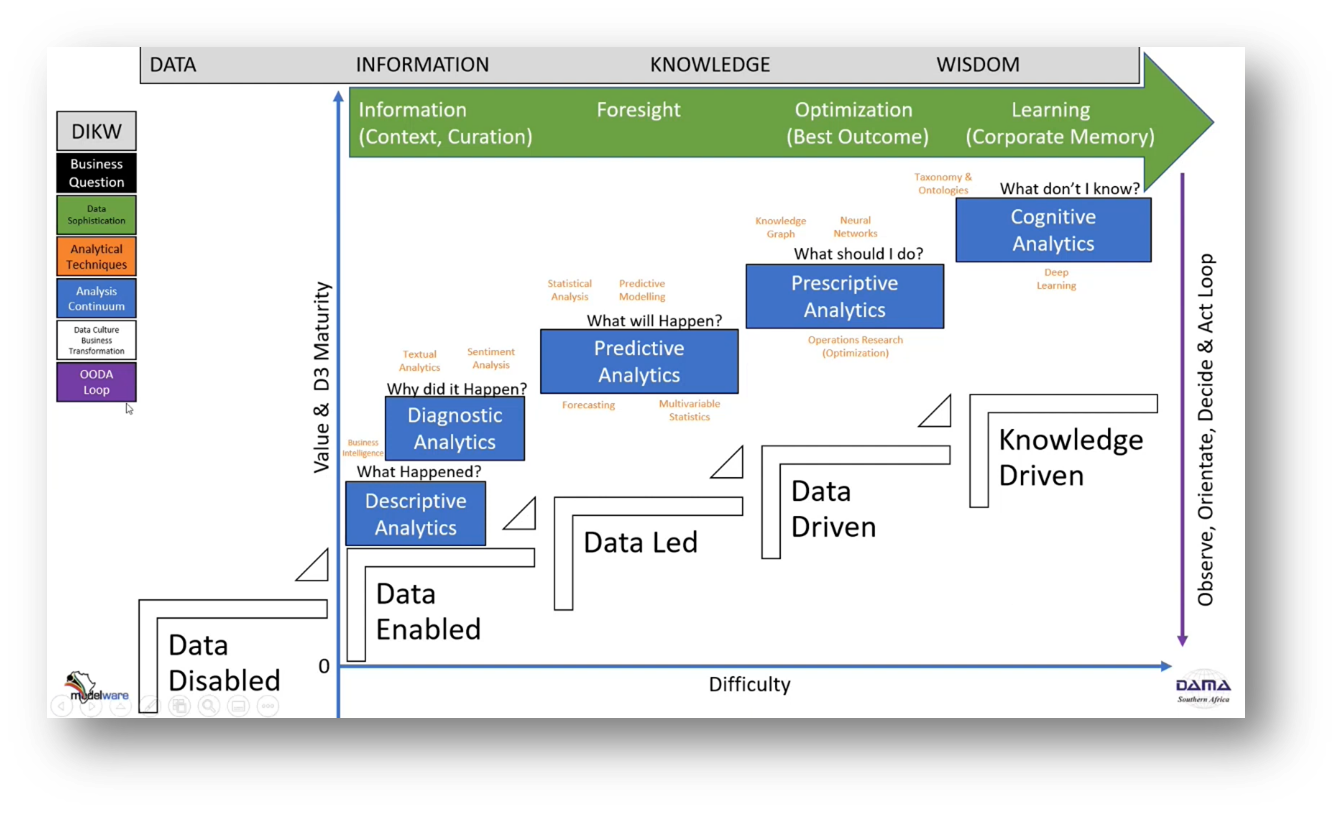
Figure 36 Decision-Making and Analytics in Business: Data, Information, Knowledge and Wisdom
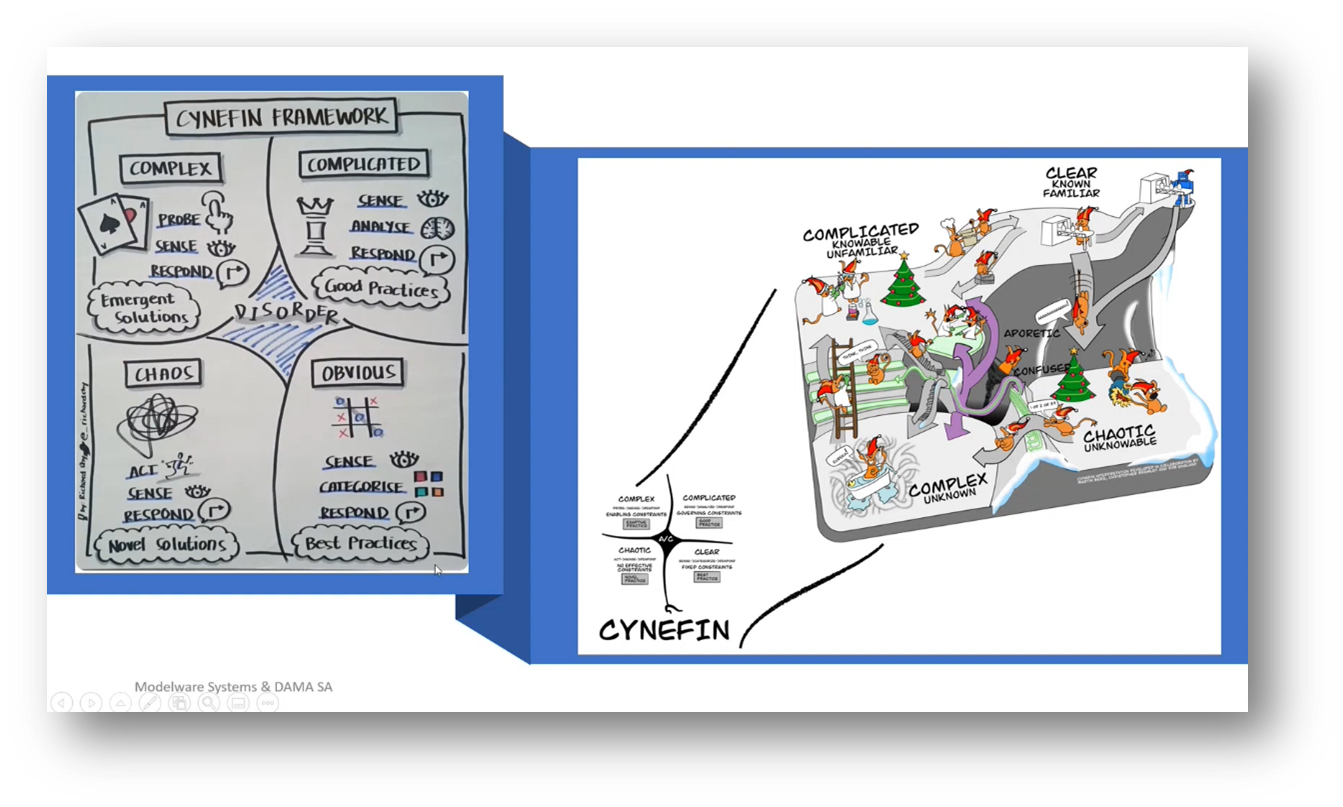
Figure 37 CYNEFIN Diagram
Challenges in Decision-making
In chaotic environments, good leadership is crucial for effective decision-making. Disorder refers to situations where decisions should not be made without careful consideration. The approach to decision-making should vary based on the context and type of analysis required. The connection framework for decision-making originated from the book "Knowledge Management for Knowledge Workers." It uses a quadrant analysis to categorise decisions and determine appropriate teams for decision-making. A different approach is required for big bet decisions that affect the entire organisation. A McKinsey paper published to support digital transformation highlighted the challenges faced by executive teams in decision-making. Executives struggle to make informed decisions due to constant surprises and lack of data. The paper identified key questions that require analytics for effective decision-making: what happened, why did it happen, what I should do, when it happens, and what I don't know.

Figure 38 Data Decision-Making Journey: Today
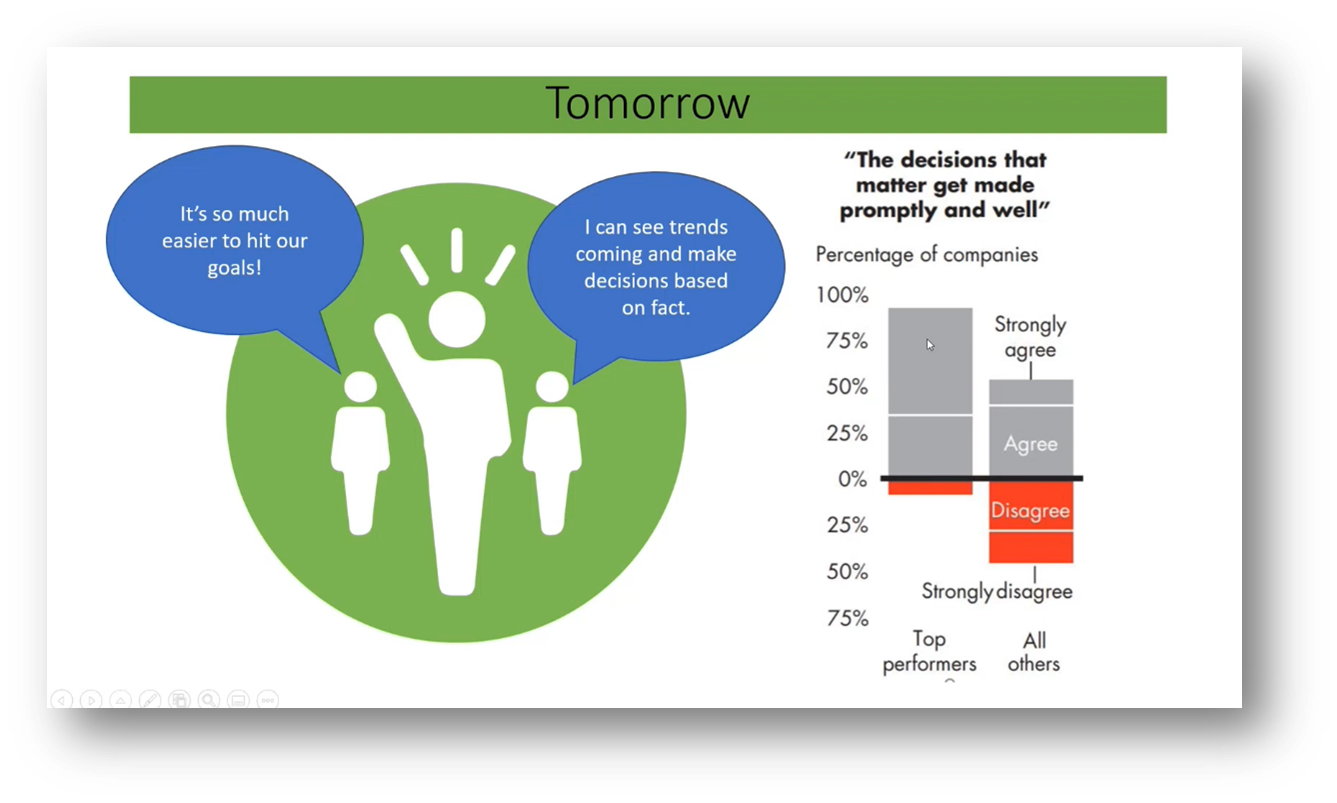
Figure 39 Data Decision-Making Journey: Tomorrow
Decision-Making Process and Framework
Howard emphasises the significance of timely and informed decision-making that minimises disagreements. He describes the common issue of spending too much time arguing due to incomplete information and a lack of data-driven techniques. The six-step framework of "decision-driven reorganising the organisation" is introduced, which involves breaking down the decision-making structure into roadmaps, considering criteria and options, offering multiple alternatives, choosing the best option, and examining the consequences to ensure decision-making assurance.
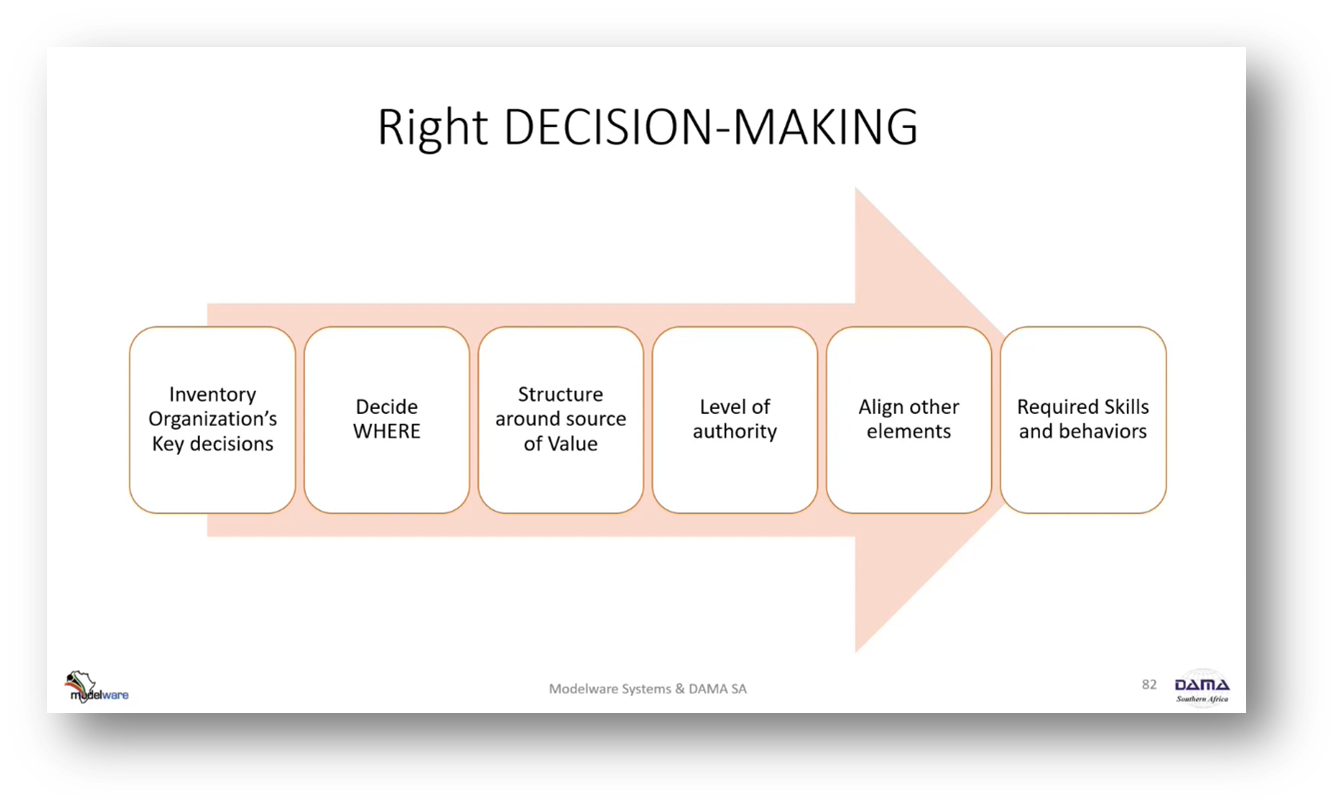
Figure 40 Right DECISION-MAKING
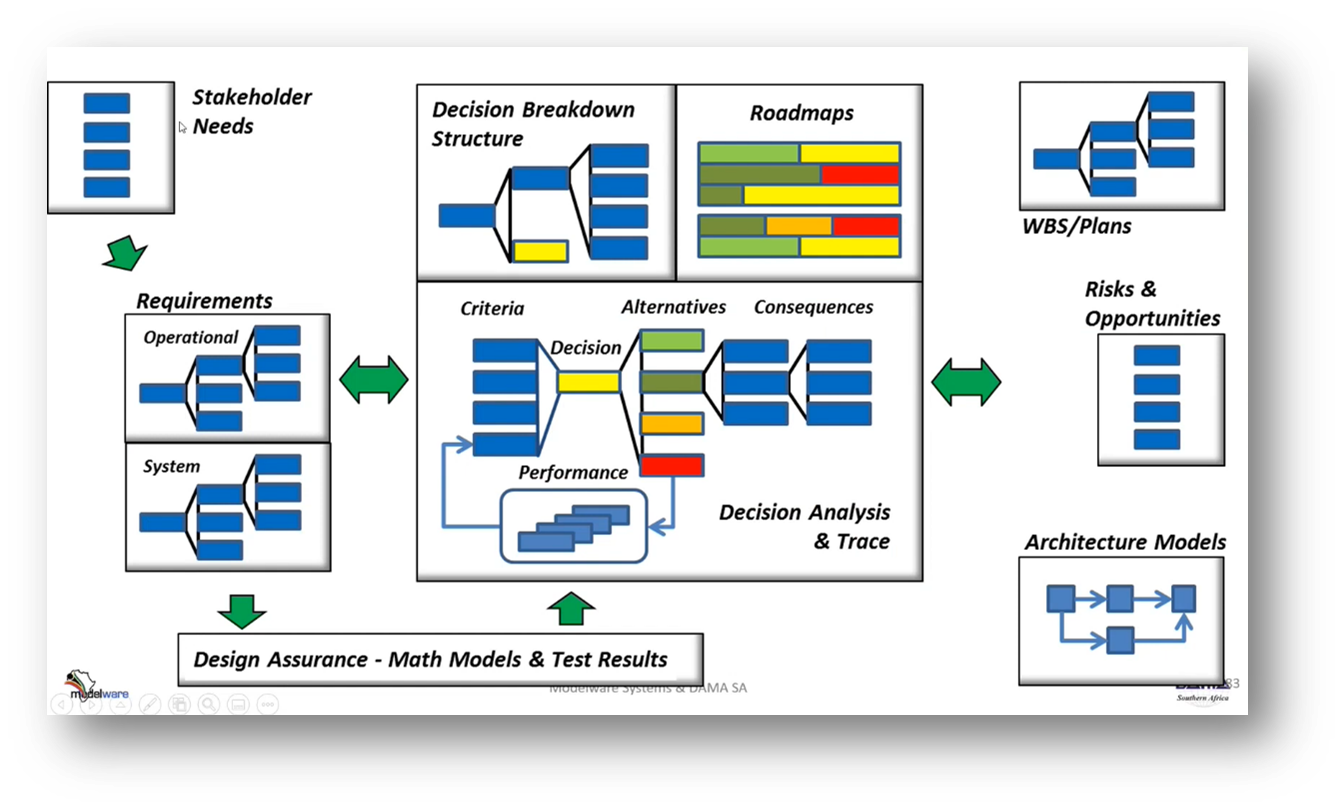
Figure 41 Decision-Making Process and Framework
Data Trust and Decision-Making
The importance of having proper storage and data to support different areas is emphasised to achieve unification in the business. The need to focus on data that helps make prompt and well-informed decisions is also highlighted. A question is raised about building trust in data, and the presenter clarified the scenario of data resistance or disability within the organisation. The benefits of descriptive analytics were discussed in understanding what happened and why, and the ability to identify the cause-effect relationship was emphasised in presenting reasons for the sales decline. Finally, the concept of cognitive memory was introduced, and the marketing team's insight into production quality issues was highlighted as a question that can be addressed using data analysis.
Better Decision-making and the Decision-Making Loop
Effective decision-making is a complex process that requires identifying the "why" behind a situation or problem. If the "why" cannot be established, alternative approaches such as predictive analytics or hypothesis testing must be considered. Trust in the answers and insights gained from understanding the "why" is crucial in utilising predictive analytics effectively. Once the "why" is established, a set of alternatives can be analysed, considering the possible outcomes at a prescriptive level. Decision-making involves evaluating alternatives, determining consequences, and choosing the right action. The starting point to improve decision-making involves understanding the "why" and utilising tools such as predictive analytics, hypothesis testing, and alternative analysis.
The CYNEFIN Approach to Decision-making
The CYNEFIN technique involves creating a connection graph of decisions, categorising them into quadrants based on cause and effect, and selecting an analytical method based on the quadrant. This approach has been used with a central bank to assess the necessary technologies and teams for innovation. It emphasises prioritising decision-making as a key metric for achieving desired business outcomes, shifting from focusing solely on data quality. Uncertain decisions are kept in a disordered area until further information is gathered. In contrast, known decisions are mapped out in the connection graph to understand better the states of information that can support the decisions.
Decision Support Systems and Modelling
Decision models play a vital role in decision support systems and come in various forms. They are related to technology and involve basic statistical modelling that compares the model's output with actual results to measure differences. This feedback loop helps improve the models and informs future decision-making. The model's output can be input or criteria for making future decisions. It is crucial to trace previous decisions and their performance for continuous improvement.
If you want to receive the recording, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!